Models & Languages Overview
An overview of Deepgram's speech-to-text models and supported languages.
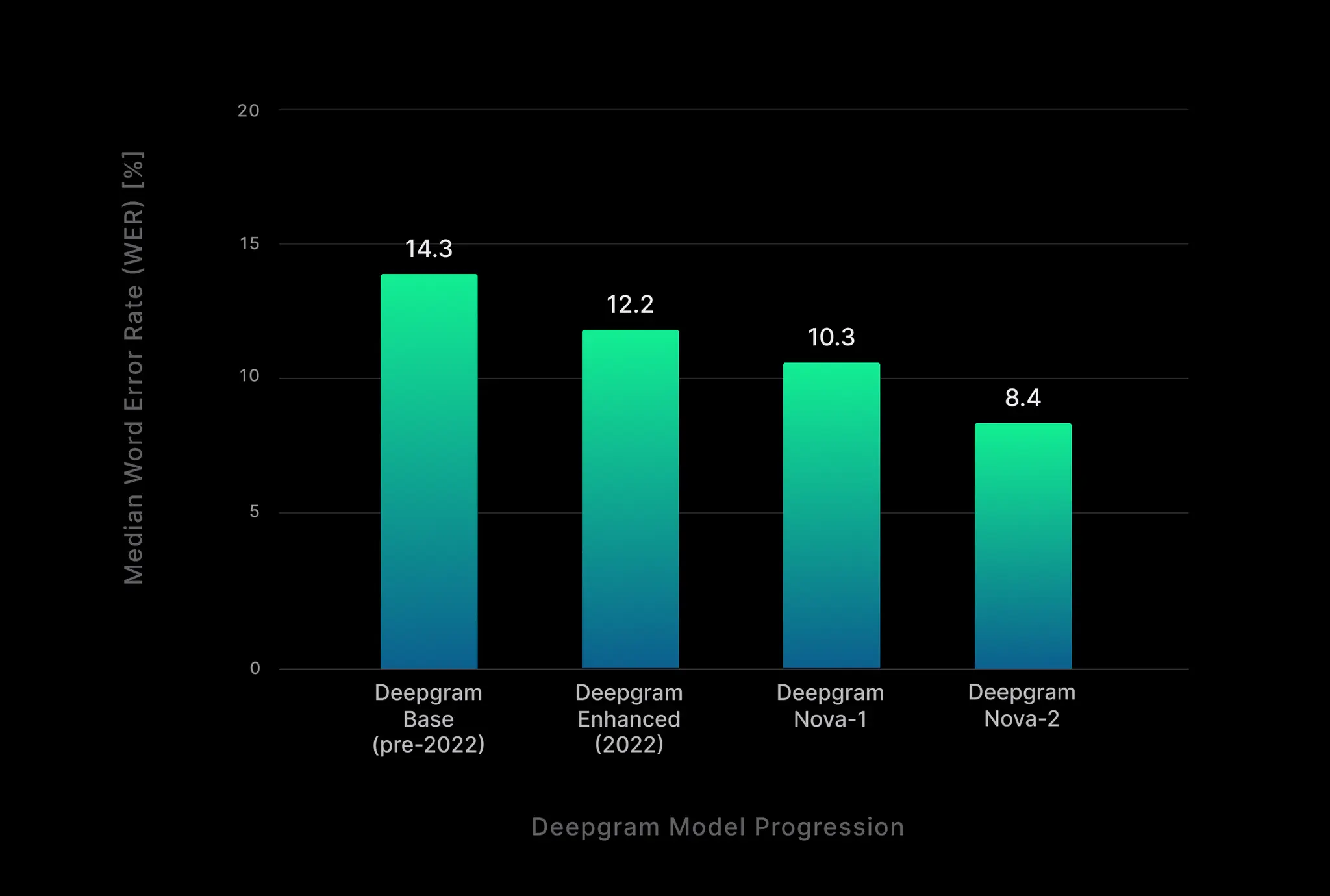
Deepgram model evolution over time. Benchmarked in 2023.
Nova-2
Recommended for readability and Deepgram's lowest word error rates. Recommended for most use cases.
Nova-2 expands on Nova-1's advancements with speech-specific optimizations to the underlying Transformer architecture, advanced data curation techniques, and a multi-stage training methodology. These changes yield reduced word error rate (WER) and enhancements to entity recognition (i.e. proper nouns, alphanumerics, etc.), punctuation, and capitalization.
Examples
The Nova-2 models can be called with the following syntax:
https://api.deepgram.com/v1/listen?model=nova-2
You can also call Nova-2 use case models with the following syntax:
https://api.deepgram.com/v1/listen?model=nova-2-phonecall
| Model | Language |
|---|---|
nova-2 or nova-2-general | Bulgarian: bgCatalan: caCzech: csDanish: da, da-DKDutch: nlEnglish: en, en-US, en-AU, en-GB, en-NZ, en-INEstonian: etFinnish: fiFlemish: nl-BEFrench: fr, fr-CAGerman: deGerman (Switzerland): de-CHGreek: elHindi: hi, hi-LatnHungarian: huIndonesian: idItalian: itJapanese: jaKorean: ko, ko-KRLatvian: lvLithuanian: ltMalay: msNorwegian: noPolish: plPortuguese: pt, pt-BRRomanian: roRussian: ruSlovak: skSpanish: es, es-419Swedish: sv, sv-SEThai: th, th-THTurkish: trUkrainian: ukVietnamese: vi |
nova-2-meeting | English: en, en-US |
nova-2-phonecall | English: en, en-US |
nova-2-finance | English: en, en-US |
nova-2-conversationalai | English: en, en-US |
nova-2-voicemail | English: en, en-US |
nova-2-video | English: en, en-US |
nova-2-medical | English: en, en-US |
nova-2-drivethru | English: en, en-US |
nova-2-automotive | English: en, en-US |
nova-2-<CUSTOM> | All available |
Nova
Recommended for readability and low word error rates.
Nova is the predecessor to Nova-2. Training on this model spans over 100 domains and 47 billion tokens, making it the deepest-trained automatic speech-to-text model to date. Nova doesn't just excel in one specific domain — it is ideal for a wide array of voice applications that require high accuracy in diverse contexts. See the benchmarks.
Examples
The Nova models can be called with the following syntax:
https://api.deepgram.com/v1/listen?model=nova
You can also call Nova use case models with the following syntax:
https://api.deepgram.com/v1/listen?model=nova-phonecall
| Model | Language |
|---|---|
nova or nova-general | English: en, en-US, en-AU, en-GB, en-NZ, en-INSpanish: es, es-419 |
nova-phonecall | English: en, en-US |
nova-medical | English: en, en-US |
nova-<CUSTOM> | All available |
Enhanced
Recommended for lower word error rates than Base, high accuracy timestamps, and use cases that require keyword boosting.
Examples
The Enhanced models can be called with the following syntax:
https://api.deepgram.com/v1/listen?model=enhanced
You can also call Enhanced use case models with the following syntax:
https://api.deepgram.com/v1/listen?model=enhanced-phonecall
| Model | Language |
|---|---|
enhanced or enhanced-general | Danish: daDutch: nlEnglish: en, en-USFlemish: nlFrench: frGerman: deHindi: hiItalian: itJapanese: jaKorean: koNorwegian: noPolish: plPortuguese: pt, pt-BRSpanish: es, es-419, es-LATAMSwedish: svTamasheq: taqTamil: ta |
enhanced-meeting | English: en, en-US |
enhanced-phonecall | English: en, en-US |
enhanced-finance | English: en, en-US |
enhanced-<CUSTOM> | All available |
Base
Recommended for large transcription volumes and high accuracy timestamps.
Examples
The Base models can be called with the following syntax:
https://api.deepgram.com/v1/listen?model=base
You can also call Base use case models with the following syntax:
https://api.deepgram.com/v1/listen?model=base-phonecall
| Model | Language |
|---|---|
base or base-general | Chinese: zh, zh-CN, zh-TWDanish: daDutch: nlEnglish: en, en-USFlemish: nlFrench: fr, fr-CAGerman: deHindi: hi, hi-LatnIndonesian: idItalian: itJapanese: jaKorean: koNorwegian: noPolish: plPortuguese: pt, pt-BRRussian: ruSpanish: es, es-419, es-LATAMSwedish: svTamasheq: taqTurkish: trUkrainian: uk |
base-meeting | English: en, en-US |
base-phonecall | English: en, en-US |
base-finance | English: en, en-US |
base-conversationalai | English: en, en-US |
base-voicemail | English: en, en-US |
base-video | English: en, en-US |
base-<CUSTOM> | All available |
Deepgram Whisper Cloud
Whisper models are less scalable than all other Deepgram models due to their inherent model architecture. All non-Whisper models will return results faster and scale to higher load.
Deepgram Whisper Cloud is a fully managed API that gives you access to Deepgram’s version of OpenAI’s Whisper model. Read our guide Deepgram Whisper Cloud for a deeper dive into this offering.
- Additional rate limits apply to Whisper due to poor scalability.
- Requests to Whisper are limited to 15 concurrent requests with a paid plan and 5 concurrent requests with the pay-as-you-go plan.
- Long audio files are supported up to a maximum of 20 minutes of processing time (the maximum length of the audio depends on the size of the Whisper model).
Deepgram's Whisper Cloud models can be called with the following syntax:
https://api.deepgram.com/v1/listen?model=whisper
https://api.deepgram.com/v1/listen?model=whisper-SIZE
| Model | Language |
|---|---|
whisper-tiny | See available |
whisper-base | See available |
whisper-small | See available |
whisper-medium OR whisper | See available |
whisper-large | See available |
Updated 1 day ago