Activation Functions
Activation functions are crucial in shaping the output of neural networks, controlling the output of the network's neurons, impacting both the learning processes and predictions of the network.
Activation functions are crucial in shaping the output of neural networks. As mathematical equations, they control the output of the network's neurons, impacting both the learning processes and predictions of the network. They achieve this by regulating the signal transmitted to the next layer, ranging from 0% (complete inactivity) to 100% (full activity). This regulation significantly influences the model's accuracy, learning efficiency, and generalization ability on new, unseen data.
Basics of Activation Functions
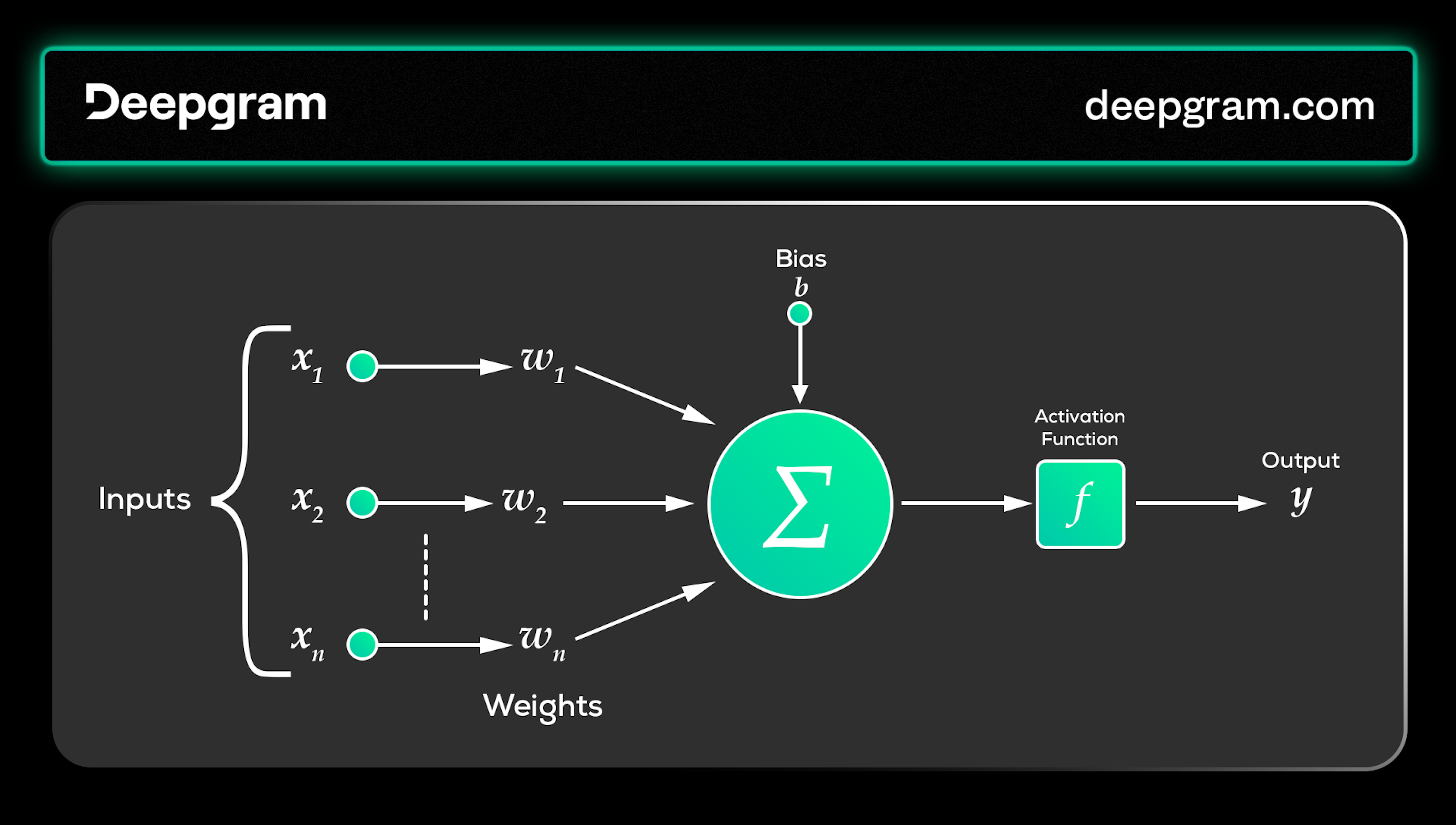
These functions are designed to work with the outputs from each layer within any neural network architecture. They act as the “gatekeepers” in neural networks, influencing what information passes through the layers and contributing to the final output. In fully connected networks, they take the weighted sum of a neuron's inputs and bias, perform a specific transformation, and map them to a designated range.
This important transformation is what enables each neuron to make a decision—to activate or not—based on the data it receives. This non-linear transformation is important, allowing the network to handle complex tasks beyond simple linear regression.
With this transformation, tasks—facial recognition, natural language processing, speech understanding, and many others—where detailed and nuanced patterns play an important role are possible.
Types of Activation Functions
There are various activation functions, each with its own unique role in influencing the flow of information within the network. These include, among many others:
Sigmoid Activation Function
Hyperbolic Tangent (tanh) Activation Function
Rectified Linear Unit (ReLU) Activation Function
Softmax Activation Function
Gated Linear Unit activation function
Swish-Gated Linear Unit Activation Function
These functions determine which node propagates information to the next layer and delivers non-linear outputs. The table below summarizes the various functions and corresponding outputs.
| Activation Function | Output |
| Sigmoid | 0 to 1 |
| Hyperbolic Tanh | -1 to +1 |
| Rectified Linear Unit (ReLU) | 0 if X<0; x otherwise |
| Softmax | Vector of probabilities with sum=1 |
| Gated Linear Unit | Output depends on the gating mechanism |
| Swish-Gated Linear Unit | Output depends on the gating mechanism |
Sigmoid Activation Function
The Sigmoid function, often represented as (x), features an S-shaped curve. This function offers a clear probability indication with a smooth and differentiable characteristic. It achieves this by mapping any input to a value within the range of 0 to 1, making it interpretable as a probability.
It can be represented mathematically as:
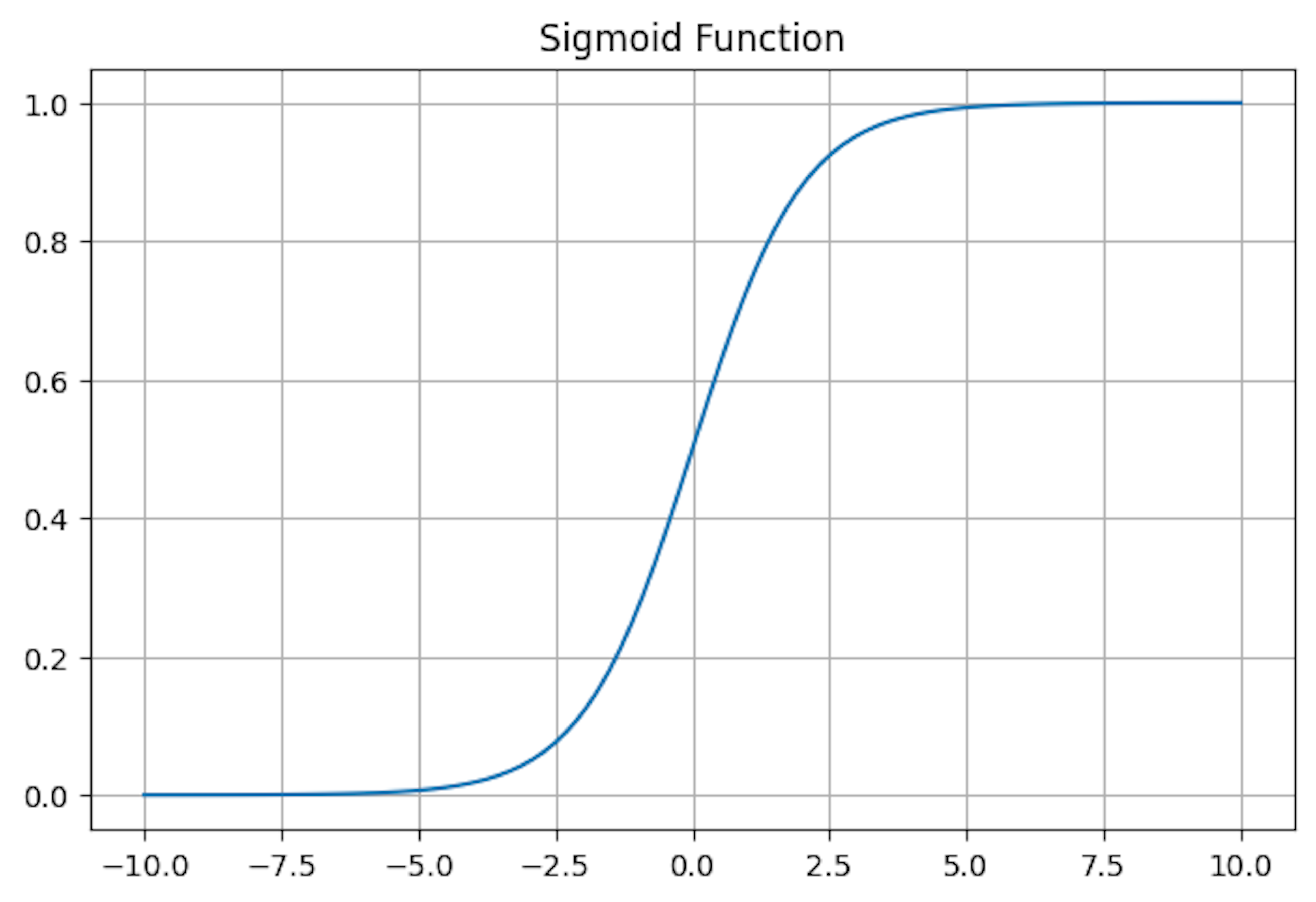
Use Cases: Sigmoid finds its niche in binary classification problems, like logistic regression, where outputs represent probabilities. Its prevalence extends to the output layer of neural networks handling tasks such as spam detection in emails, where the requirement is to output a probability score.
Pros and Cons: While intuitive and useful for binary outcomes, sigmoid functions suffer from the vanishing gradient problem, making them less effective in deep networks.
Hyperbolic Tangent (tanh) Activation Function
Like the sigmoid function, Tanh excels at centring data with an output range of -1 to 1. This means the negative inputs will be mapped strongly negative, and the zero inputs will be near zero in the output.
The tanh function is represented as:
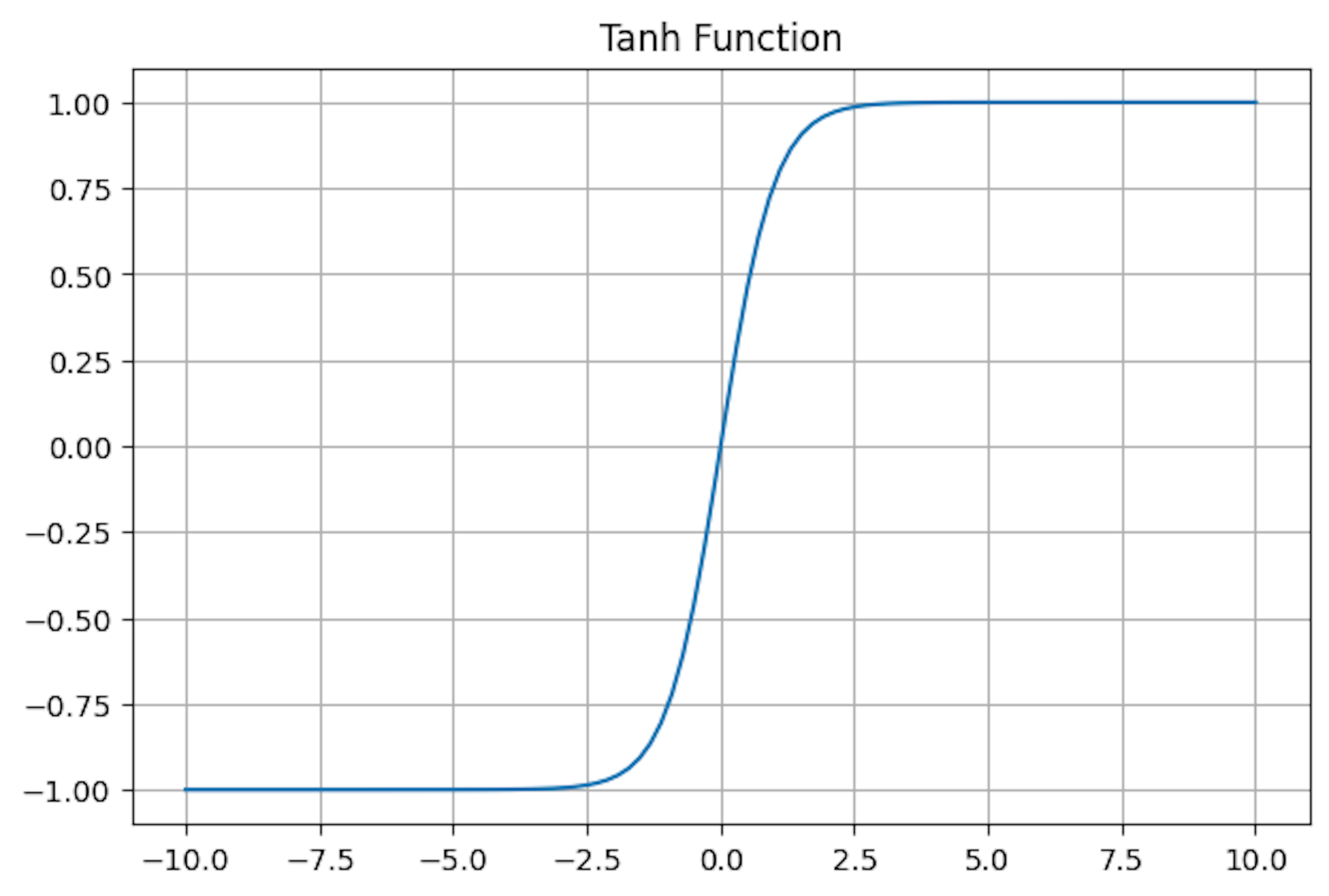
Use Cases: Tanh is often used in hidden neural network layers as its values lie between -1 and 1, aiding in centering the data for enhanced learning in subsequent layers. It’s instrumental in scenarios where standardization of input is required. Due to its effectiveness in handling time-series data, it was used in earlier LSTM networks for sequence modeling.
Pros and Cons: Tanh compresses the input values into a smaller range, making it particularly useful for tasks where the input data has strong negative and positive components, such as image classification. However, it also suffers from the vanishing gradient problem.
Softmax Activation Function
The Softmax function extends the concept of the sigmoid function to handle multiple classes. It mainly converts vectors of real-valued numbers into a probability distribution. Each output value represents the probability that the input belongs to a particular class.
Given a vector Z consisting of real numbers Z = [z1 ,z2 ...,zk ] where ‘k’ is the total number of classes, the Softmax function is applied to each element zi of this vector to transform the vector into a probability distribution, where each element (Z)i represents the probability that the input belongs to the ith class.
It is mathematically represented as:
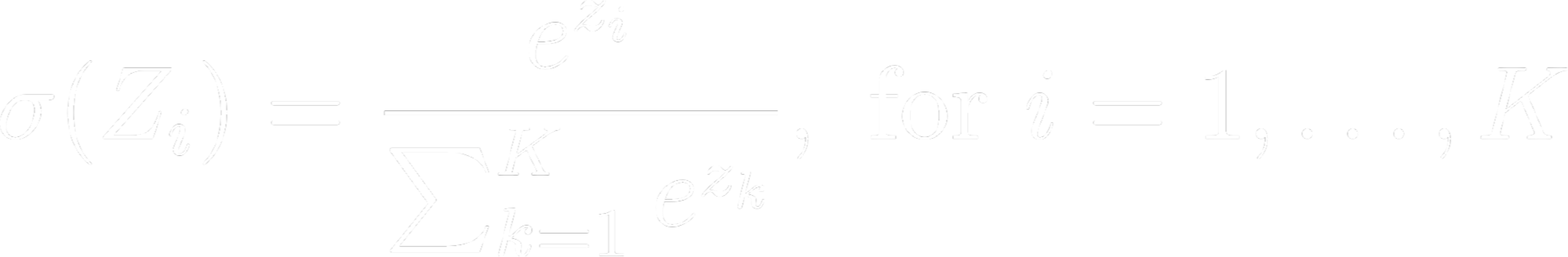
Basically, this computation makes sure that the output values are always within the range (0, 1) and add up to a total of 1.
Use Cases: Its key application is classifying inputs into multiple categories, particularly in the output layer of neural networks. This is commonly applied in tasks like image recognition, where the goal is to categorize images into distinct classes (e.g., animals, cars, fruits).
Pros and Cons: It’s effective for multiclass classification but computationally intensive, especially with many target classes.
Rectified Linear Unit (ReLU) Activation Function
ReLU is a piecewise linear function that results in the input directly if it is positive. Otherwise, it outputs zero. This characteristic makes it computationally efficient, as it simplifies the calculations during the forward and backward passes in neural network training. Known for its simplicity and effectiveness, ReLU introduces non-linearity without affecting the receptive fields of convolutional layers.
Is mathematically defined by the function:
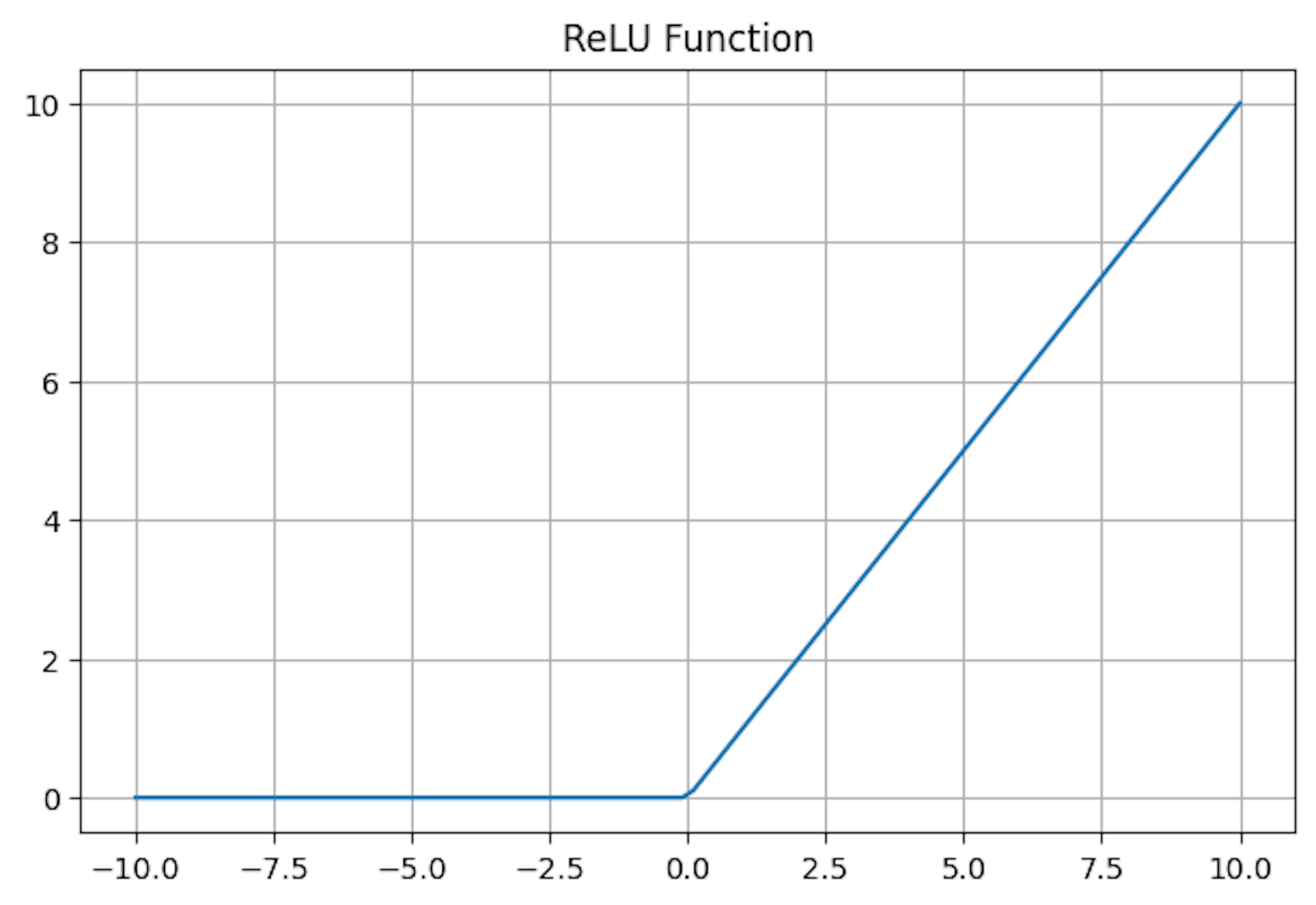
Variants of ReLU: Variants like Leaky ReLU and Parametric ReLU address the problem of dying neurons (where a neuron might consistently output 0). These variants allow a small, non-zero gradient when the unit is inactive, thereby keeping the neurons alive in the training process.
Use Cases: Many types of neural networks use ReLU as their default activation function because it speeds up convergence in stochastic gradient descent better than sigmoid or tanh functions. Its notable efficiency makes it especially advantageous in Convolutional Neural Networks (CNNs) and other deep learning models, leading to its adoption in advanced object detection frameworks such as YOLO (You Only Look Once), significantly contributing to their state-of-the-art performance.
Pros and Cons: While ReLU speeds up training, it can suffer from the dying ReLU problem, where neurons stop responding to inputs.
Gated Linear Unit (GLU) activation function
GLU applies a gating mechanism to linear units. It is mathematically expressed as a combination of linear and non-linear components, allowing the network to learn to control the flow of information more dynamically.
This mathematical representation can vary depending on the implementation, but a common formulation follows the following:
Given an input vector X, two sets of weights W and V, and bias b, the GLU can be represented as:
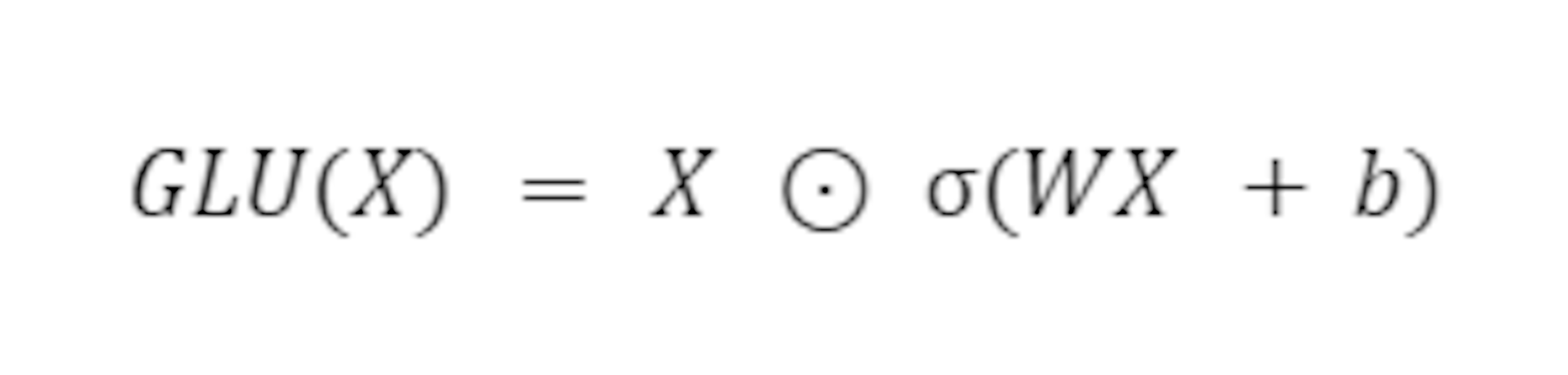
where σ represents the sigmoid activation function
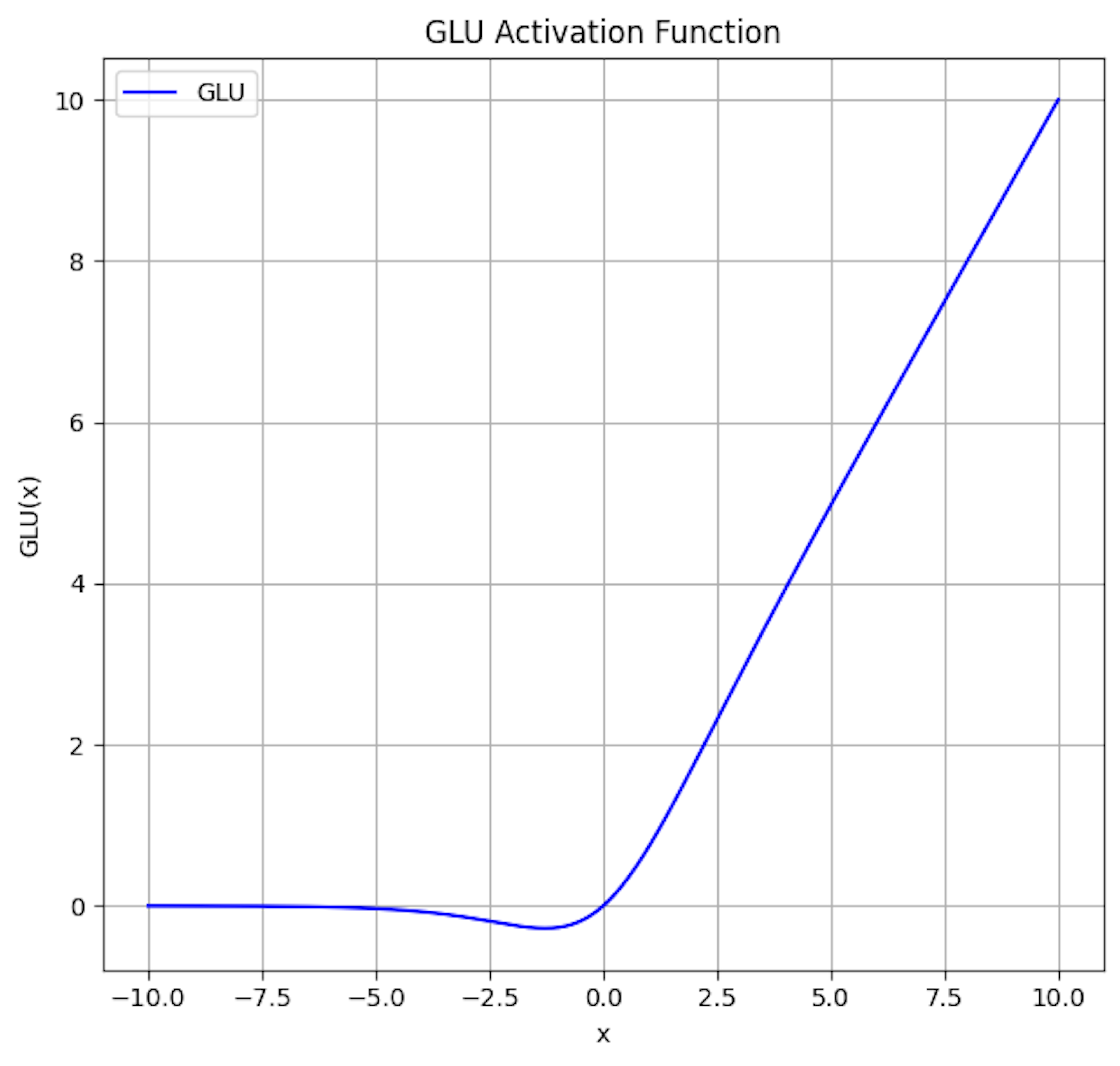
This allows the GLU to control the flow of information from the input X by learning which parts to emphasize or de-emphasize through the gating mechanism.
Use Cases: GLU has shown promise in natural language processing and sequence modeling. Its ability to regulate information flow is especially beneficial in recurrent neural networks and LSTMs. OpenAI's GPT-3 notably employs GLU variants to control information flow, contributing to its proficiency in generating contextually relevant and coherent text.
Pros and Cons: Provides dynamic learning capabilities but introduces added complexity to the model.
Swish-Gated Linear Unit Activation Function (SwiGLU)
SwiGLU is a variant of the GLU function that integrates the Swish activation function. Swish combines ReLU and Sigmoid properties, offering a smooth, non-monotonic function with a non-zero gradient for all inputs. Its output is bounded below and unbounded above.
The Swish function is defined as:
Where x is the input to the function, is the sigmoid function, and is either a constant or a trainable parameter.
Given an input vector X , a set of weights W and bias b, the SwiGLU can be represented as:
Use Cases: It is useful for minimizing vanishing gradients, especially in deeper models. The Swish function allows for a more balanced activation, which has been found to improve the performance of deep neural networks in complex tasks like image classification and language translation. In NLP models like Meta's LLaMA-2, SwiGLU handles complex linguistic data.
Pros and Cons: It offers a balance between linearity and non-linearity but requires careful tuning of parameters.
Activation Functions in Deep Learning Architectures
In deep learning, activation functions do more than determine individual neuron outputs. They define the behavior and learning capabilities of the entire network. Applied uniquely across layers, each activation function serves a distinct purpose, to enhance the network's ability to process and learn from complex data.
Role of Activation Functions in Different Layers of a Neural Network
Input Layer: Typically, activation functions are not used in the input layer; the input data is fed directly to the next layer.
Hidden Layers: This is where activation functions play a crucial role. Functions like ReLU and its variants (Leaky ReLU, Parametric ReLU), tanh, and GLU are commonly used in these layers. These functions introduce non-linearity, allowing the network to learn complex patterns and relationships in the data.
Output Layer: The choice of activation function in the output layer depends on the specific task. A sigmoid function often outputs a probability between 0 and 1 for binary classification. The Softmax function is preferred for multiclass classification as it provides a probability distribution across multiple classes.
Handling Vanishing and Exploding Gradient Problems with Activation Functions
Vanishing Gradient Problem: This occurs when gradients become very small, halting the training process of the network. This issue is common with activation functions such as sigmoid and tanh, as they tend to saturate at extreme input values (especially in deep networks). ReLU and its variations are used to counteract this, as they preserve larger gradients over various inputs, thus aiding in reducing this problem.
Exploding Gradient Problem: This happens when gradients become excessively large, causing unstable network updates. Techniques such as gradient clipping and activation functions that do not exponentially increase the gradient (like ReLU) can help control this problem.
Choosing the Right Activation Function
Choosing the right activation function for a neural network is a critical decision that can significantly influence the network's training dynamics, learning efficiency, and overall performance. This choice should be made considering the specific characteristics of the data, the architecture of the network, the nature of the problem being solved etc
Network Architecture: Selecting the ideal activation function for a neural network hinges on the network's architecture. In Convolutional Neural Networks (CNNs), ReLU and its variants excel in processing visual data and addressing vanishing gradient issues.
On the other hand, Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks may benefit from tanh and sigmoid functions, adept at handling time-dependent data.
Problem Type: Sigmoid functions are ideal for binary classification problems, particularly in the output layer, due to their probabilistic output. The Softmax function is preferred for multi-class classification tasks because it produces a probability distribution across various classes. ReLU and its variants are generally suited for general purposes across various network types due to their non-saturating nature and efficiency.
Computational Efficiency: The computational load of different activation functions could affect your choice, especially in large-scale deep learning models. ReLU is known for its computational efficiency and simplicity, making it a popular choice in many deep learning applications. While potentially offering better performance in certain contexts, more complex functions like Swish or GLU are more computationally intensive. They may not be suitable for all scenarios, particularly where computational resources are limited.
Gradient Flow: Activation functions that maintain a healthy flow of gradients, such as ReLU and its variants, are essential in deep learning models to ensure effective learning and convergence. The choice of function should minimize the risk of vanishing or exploding gradients, which can significantly hinder the training process of deep neural networks.
Conclusion
In conclusion, activation functions are not mere mathematical tools; they are the essence that empowers neural networks to learn, adapt, and make intelligent decisions. Their selection requires a deep understanding of the network's architecture, the nature of the problem, computational constraints, and the complexities of gradient flow. With the advancement of machine learning, activation functions will undoubtedly play a central role in determining the future of artificial intelligence and its ability to mimic human cognitive capabilities and even surpass them one day.