Backpropagation
Backpropagation is the backbone of neural network training, the silent architect behind many advancements in deep learning and AI. This article illuminates the often complex realm of backpropagation, offering hands-on insights into its practical application.
Have you ever pondered how artificial intelligence systems such as Siri or Alexa process your requests with such acumen? At the core of these technologies lies a critical process known as backpropagation. It's the backbone of neural network training, the silent architect behind many advancements in deep learning and AI. This article illuminates the often complex realm of backpropagation, offering hands-on insights into its practical application. Prepare to dive into the mathematical foundations that power this process, explore a tangible backpropagation example, and learn how to implement this powerful tool in Python. So, are you ready to unravel the mysteries of neural networks and elevate your understanding of AI? Let's begin the journey into the world of backpropagation, where numbers and neurons converge to create intelligence.
Backpropagation is an integral aspect of neural network training, pivotal in the advancement of deep learning and AI.
Backpropagation stands as the cornerstone of neural network training, a mathematical conductor orchestrating the harmony between predictions and reality. Here's why it's crucial:
It adjusts the weights within a network meticulously, ensuring precision in the model's forecasts.
By minimizing the loss function, backpropagation keeps the predictions error at bay, fine-tuning the network's output to align with actual data.
The power of backpropagation lies in its iterative nature, with each epoch inching closer to reduced loss and enhanced accuracy.
This article doesn't just skim the surface. It delves deep into backpropagation's mathematical bedrock, offers a pragmatic backpropagation example, and showcases its implementation in Python—a language synonymous with AI innovations. Whether you're a seasoned data scientist or an AI enthusiast, the insights here will bolster your understanding and application of this pivotal process.
Section 1: What is backpropagation mathematically?
Backpropagation, often visualized as the central cog in the wheel of neural network training, is more than just an algorithm; it's a mathematical odyssey from error to accuracy. This section unpacks the layers of calculus and logic that define backpropagation and its pivotal role in the evolution of AI.
Defining Backpropagation and its Role
Backpropagation: A mathematical technique used during neural network training to optimize the weights of neurons.
Primary Function: To adjust these weights methodically, backpropagation minimizes the loss function, essentially a performance metric that quantifies the disparity between predicted output and actual output.
End Goal: Achieve the lowest possible loss, indicating the highest accuracy of the neural model in making predictions.
The Loss Function: A Measure of Network Performance
Loss Function Significance: Acts as a compass for the training process, guiding weight adjustments to improve the model’s prediction accuracy.
Common Examples: Mean Squared Error (MSE) for regression tasks or Cross-Entropy for classification problems.
Performance Indicator: The lower the value of the loss function, the closer the neural network's predictions are to the true values.
The Feedforward Process: Inputs to Outputs
Process Overview: Neural networks propagate input data forward through layers to produce an output.
Layer Transformation: Each layer consists of neurons that apply weights and biases to the input data, followed by activation functions that introduce non-linearity, enabling the network to learn complex patterns.
Resulting Output: The final layer yields the predicted output, which is then compared to the actual output to compute the loss.
The Derivative's Role in Backpropagation
Gradients Calculation: Backpropagation computes gradients of the loss function concerning each weight using partial derivatives.
Purpose of Derivatives: To determine the direction and magnitude by which the weights need to be adjusted to reduce loss.
Partial Derivative: Let's say we denote the loss function as L and weight as w, the partial derivative (∂L/∂w) indicates how a change in weight w affects the loss L.
The Chain Rule: Foundation of Backpropagation
Chain Rule Essence: A calculus principle that breaks down the computation of derivatives for composite functions.
Backpropagation Application: Enables the calculation of gradients for weights deep in the network by working backward from the output layer to the input.
Gradient Computation: The chain rule is applied repetitively to propagate the error backward through the network’s layers.
Learning Rate: Balancing Convergence and Stability
Learning Rate Definition: A hyperparameter that determines the size of the steps taken during the weight update process.
Impact on Training: A higher learning rate may hasten convergence but risks overshooting the minimum loss; a lower rate ensures stability but may slow down the learning process.
Optimization: The learning rate is often fine-tuned to achieve a balance between rapid convergence and the stability of the training process.
Iterative Nature: Epochs and Convergence
Training Epochs: Each full cycle through the entire training dataset is known as an epoch.
Iterative Updates: With each epoch, the network undergoes a series of forward and backward passes, adjusting weights incrementally to minimize loss.
Convergence Goal: The iterative process continues until the loss function reaches a plateau or a predefined threshold, indicating that the model has learned the data patterns efficiently.
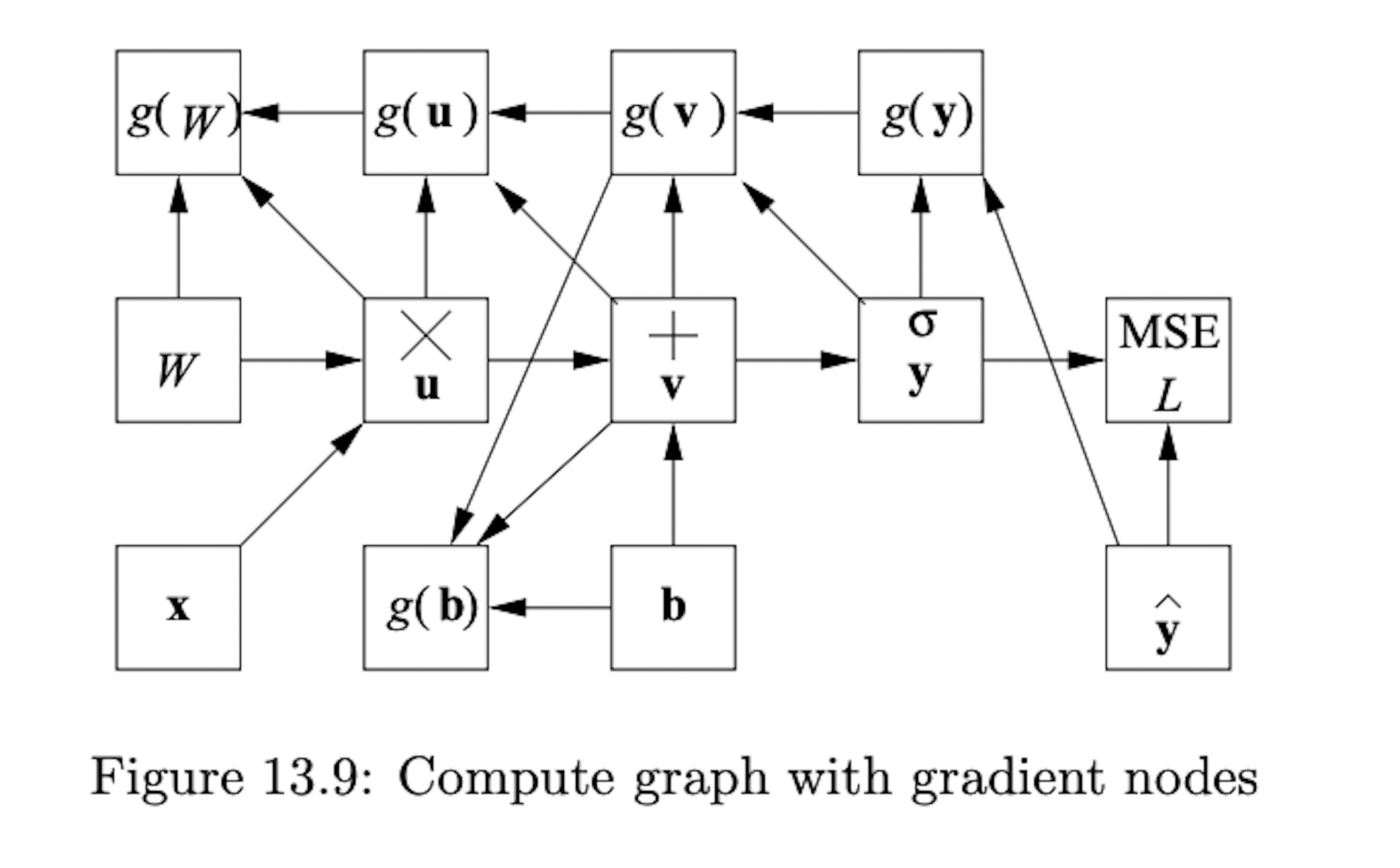
To explore a detailed mathematical derivation of backpropagation, consider reviewing the explanation provided in Section 13.3.3 of this PDF from Stanford University’s text on Mining Massive Datasets. The image below also comes from this source. This resource can serve as a valuable reference for those seeking a deeper understanding of the computations involved in backpropagation.
Section 2: An example of backpropagation in practice
To anchor the theoretical concepts of backpropagation firmly in practical application, let's navigate through a hands-on example. This exercise will illuminate the dynamics of a neural network as it learns, adapts, and strives for precision. The journey from input to a refined model unfolds in several layers, each playing a critical role in the network's education.
Basic Neural Network Architecture
Architecture Blueprint: Envision a simple network structure comprising an input layer, one hidden layer, and an output layer.
Neurons: Each layer hosts multiple neurons: the input layer neurons correspond to the feature size of the data, the hidden layer neurons process the inputs, and the output layer neurons make the final prediction.
Weights and Biases: Neurons are interconnected by weights, and each neuron has an associated bias, both of which are tuned during training to minimize prediction errors.
Sample Dataset for Training
Dataset Introduction: Consider a dataset with inputs such as features of houses (size, number of bedrooms) and expected outputs like house prices.
Objective: The model learns to predict prices based on the input features using the pattern it discerns through training.
Forward Pass Calculation
Input Feeding: Present the network with a set of input features.
Transformation: The input data is weighted, biases are added, and the result passes through an activation function.
Output Generation: Calculate the predicted output, which at the initial stages is a rough estimate due to random initialization of weights and biases.
Loss Function Calculation
Error Measurement: Employ the mean squared error function to quantify the difference between the network's predictions and the actual prices.
Loss Interpretation: The resulting value is a measure of the network's performance; the lower the loss, the more accurate the predictions.
Backward Pass: Gradient Computation
Error Backpropagation: Calculate the gradients of the loss function with respect to each weight and bias by applying the chain rule.
Gradient Significance: These gradients inform the direction in which the weights and biases should be adjusted to reduce prediction error.
Weight Update for Loss Minimization
Learning Rate Application: Apply a small learning rate to the gradients to ensure controlled updates.
Adjustment Direction: Modify the weights and biases in the opposite direction of the gradients.
Update Mechanism: This step nudges the network weights and biases incrementally towards values that lower the loss function.
Iterative Improvement through Training
Repeated Epochs: Through multiple epochs, witness the network's predictions evolve and become more accurate.
Gradual Refinement: Each iteration of forward and backward passes, followed by weight updates, leads to a decrease in loss and an increase in prediction accuracy.
Convergence Tracking: Monitor the loss across epochs to ensure it diminishes, signaling successful learning.
For an enriched understanding and a step-by-step visualization of this process, Matt Mazur's article stands as an exemplary guide, diving deep into the granular details of each step in the backpropagation journey. By following along, one can witness the transformation of a basic neural network, through the meticulous process of backpropagation, into an insightful predictive model.
Section 3: Backpropagation Implementation in Python
After laying the foundation with a theoretical understanding and walking through a practical backpropagation example, it's time to roll up our sleeves and dive into the actual code. Python, renowned for its simplicity and readability, is the chosen language for this endeavor. This section will guide you through setting up your Python environment for neural network implementation, defining your architecture, and bringing the backpropagation algorithm to life.
Setting up the Python Environment
Tool Selection: Choose tools like NumPy for numerical computation and TensorFlow for a more high-level neural network API.
Installation: Use pip install numpy tensorflow or a similar command to add these libraries to your Python environment.
Verification: Confirm the installation by importing the libraries in a Python script and checking their version to ensure compatibility.
Defining the Neural Network Architecture
Blueprinting: Draft a clear architecture, deciding the number of layers and the neurons in each layer.
Activation Functions: Select activation functions such as ReLU or Sigmoid to introduce non-linearity into the network.
Coding Structure: Define this network architecture using Python classes or TensorFlow's Keras API for an organized and scalable codebase.
Implementing the Forward Pass Function
Input Processing: Code the function to accept inputs and pass them through the network layers.
Weights and Biases: Ensure the weights and biases are initialized and properly incorporated into the calculations.
Activation Application: Apply the chosen activation functions to the weighted sums to obtain the output from each neuron.
Coding the Loss Function
Error Quantification: Implement a loss function, like mean squared error, to evaluate the network's performance.
Pythonic Implementation: Use Python's mathematical capabilities to code the loss function efficiently and accurately.
Integration: Seamlessly integrate the loss function into the network's training pipeline.
Developing the Backpropagation Function
Gradient Computation: Write the function to compute the gradient of the loss with respect to the weights and biases using backpropagation.
Chain Rule: Ensure the chain rule is properly applied in the function to calculate the gradients through the layers.
Weight Updates: Incorporate the learning rate and update the weights and biases in the direction that minimizes the loss.
Integrating a Training Loop
Epoch Management: Set up the training loop to iterate through a specified number of epochs.
Forward and Backward Passes: Within each epoch, perform forward passes and backpropagation to adjust the model.
Progress Tracking: Maintain a log of the loss over the epochs to monitor the learning progress and convergence.
Testing the Python Implementation
Dataset Preparation: Select a simple dataset to train and test the neural network's implementation.
Training Execution: Run the network through the training loop, feeding in the data and refining the model.
Evaluation: Assess the model's performance and learning progression by observing the changes in loss over time.
To enhance your understanding and provide a concrete codebase reference, the tutorial on Machine Learning Mastery illustrates how to code a neural network with backpropagation in Python. This resource offers a detailed walkthrough, complementing the steps outlined here and serving as a practical companion to your implementation journey. With these tools and guidelines, you're well on your way to mastering backpropagation in Python, bridging the gap between theory and application.