Inference Engine
An inference engine stands as the core component of an artificial intelligence system, vested with the responsibility of deriving new insights by applying logical rules to a knowledge base. This sophisticated element of AI systems mirrors human reasoning by interpreting data, inferring relationships, and reaching conclusions that guide decision-making processes.
What is an Inference Engine?
An inference engine stands as the core component of an artificial intelligence system, vested with the responsibility of deriving new insights by applying logical rules to a knowledge base. This sophisticated element of AI systems mirrors human reasoning by interpreting data, inferring relationships, and reaching conclusions that guide decision-making processes.
Defining the Inference Engine
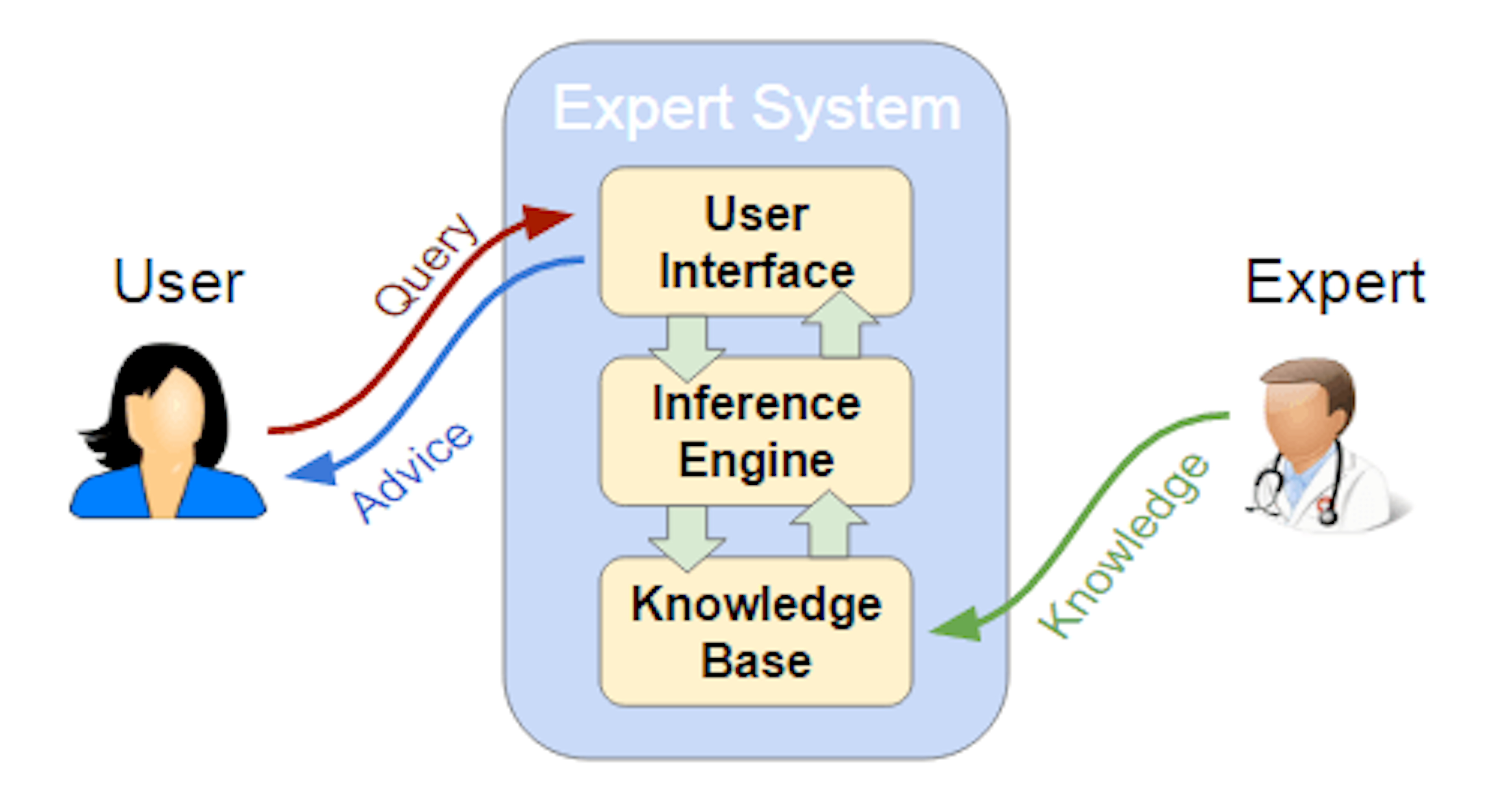
At its essence, an inference engine forms a crucial segment of an AI's anatomy, allowing the system to make logical leaps from known information. It operates by:
Processing Information: Just as a human brain would, the engine scrutinizes and interprets the data housed within the knowledge base.
Applying Rules: It then strategically applies a set of predefined logical rules to this data.
Deducing Insights: Through this process, the engine can deduce new insights, much like solving a puzzle by fitting pieces of information together to form a broader picture.
In other words, it infers new information or general conclusions from any initial data given, just like a detective follows clues to uncover the truth.
The Role in Expert Systems
Historically, inference engines have played a foundational role in expert systems, serving as their intellectual engine. These systems:
Leveraged the engine's capabilities to simulate expert-level decision-making in specific domains.
Relied on a well-structured set of rules that represented the knowledge of human experts.
Utilized the inference engine to navigate through this rule set, making decisions that would otherwise require human expertise.
Simulating Human-Like Reasoning
The mechanisms employed by inference engines are a testament to the sophistication of AI's mimicry of human cognition. They:
Use heuristic approaches to simulate the problem-solving capabilities of the human mind.
Adapt and learn from new data inputs, refining their rule application strategies over time.
Offer explanations for their reasoning, providing transparency into the AI's thought process, a feature that's particularly useful when humans need to understand and trust the decisions made by the AI.
Decision Making and Predictions
Inference engines don't just process data; they anticipate outcomes and inform actions. They are instrumental in:
Predicting future events, much like a weather forecast model that predicts weather based on past patterns and current conditions.
Automating decision-making, allowing systems to operate independently in dynamic environments, whether it be in financial markets or autonomous vehicles.
Critical Function in AI Operations
The inference engine's role extends far beyond mere data processing; it is a dynamic participant in the AI ecosystem. This includes:
Integrating with machine learning models to refine decision-making capabilities.
Optimizing performance across various applications, from natural language processing to image recognition.
Ensuring real-time responsiveness in applications where immediate decision-making is crucial.
Authoritative References
To understand the depth and breadth of inference engines, one must consider the comprehensive explanations provided by authoritative sources such as Wikipedia, Techopedia, and Britannica. These resources elucidate the technical intricacies and the evolution of inference engines from early rule-based systems to today's advanced AI applications.
Inference engines, therefore, stand at the crossroads of data and discernment, embodying the transformative power of AI to replicate and even surpass human cognitive functions in specialized tasks. Through their relentless processing and logical deductions, they empower machines with the ability to reason, predict, and decide, driving the future of intelligent systems.
Components of an Inference Engine
The inference engine's multifaceted nature is reflected in its architecture, which comprises several key components, each fulfilling a distinct role in the AI reasoning process. By dissecting the engine's structure, we gain insights into how AI systems mimic complex cognitive tasks, transforming raw data into actionable knowledge.
Knowledge Base: The Repository of Facts and Rules
At the core of the inference engine lies the knowledge base, a repository brimming with facts and rules that represent the system's understanding of the world. It is akin to a library where:
Facts serve as the foundational truths upon which reasoning builds.
Rules act as the logical constructs that guide the inference process.
A dynamic database constantly evolves as new information integrates into the system.
The integrity and extensiveness of the knowledge base directly influence the engine's capacity to reason and infer.
Inference Rules and Algorithms: The Logic Crafters
The inference engine's ability to deduce new information hinges on the sophisticated interplay between its rules and algorithms. These algorithms are the artisans of logic, skillfully crafting pathways through the knowledge base:
Inference rules outline the methods for combining or transforming facts.
Algorithms determine the sequence and conditions under which rules apply.
Logic paradigms, such as propositional and predicate logic, provide the framework for rule construction.
User Interface: The Conduit for Interaction
For an inference engine to be practical, it must have an interface through which users can interact with it. This interface functions as:
A portal for users to query the system and input new data.
A display where the engine's inferences become accessible to users.
An interactive space that enables the customization of queries and the exploration of the engine's capabilities.
Working Memory: The Temporary Fact Holder
Working memory in an inference engine is akin to scratch paper used in complex calculations. It temporarily stores:
Transient facts that emerge during the inference process.
Intermediate results that are necessary for ongoing reasoning tasks.
Contextual data that supports the current session of problem-solving.
The agility of the working memory is crucial for the engine's efficiency in reaching conclusions.
Explanation Facility: The Reasoning Revealer
Transparency in AI decision-making is vital, and the explanation facility serves this purpose by:
Justifying conclusions drawn by the inference engine.
Detailing the reasoning process including which rules were applied and how they led to a particular inference.
Building trust by allowing users to understand and verify the engine's logic.
Knowledge Acquisition Facility: The Update Mechanism
To remain accurate and relevant, an inference engine must continuously learn. The knowledge acquisition facility is responsible for:
Incorporating new facts and rules into the knowledge base.
Refining existing knowledge to reflect new insights or corrected information.
Ensuring the system adapts to changes in the domain it operates within.
The insights from ScienceDirect and other technical articles highlight the intricate architecture of inference engines, demonstrating their crucial role in advancing the frontier of artificial intelligence. By understanding these components, we appreciate not only how they function but also the magnitude of their potential to revolutionize the way machines process and apply knowledge.
Techniques Used by Inference Engines
In the intricate world of artificial intelligence, inference engines play a pivotal role in emulating the nuanced process of human cognition. By leveraging well-defined reasoning strategies, these engines sift through data, forging pathways to conclusions with the precision of a master craftsman. Let's delve into the two primary reasoning strategies that empower inference engines: forward chaining and backward chaining.
Forward Chaining: The Data-Driven Approach
Forward chaining represents a methodical, data-driven approach where the engine begins with known facts and incrementally applies inference rules to uncover additional data. This technique unfolds as follows:
Initial Data Analysis: The engine scans the knowledge base to identify what initial facts are available.
Rule Application: It applies logical rules to these facts, generating new information piece by piece.
Iterative Process: This process continues, with the engine systematically using newly inferred facts as a basis for further inferences.
The potency of forward chaining lies in its ability to expand the horizon of what is known, transforming individual data points into a comprehensive picture.
Backward Chaining: The Hypothesis-Testing Approach
In stark contrast to forward chaining, backward chaining commences with a hypothesis or a goal and traces its way back through the knowledge base to validate it. This strategy involves:
Goal Identification: Establishing what needs to be proved or concluded.
Backtracking: Searching for rules that could lead to the hypothesis and checking if the preconditions of these rules are satisfied.
Validation: Confirming the hypothesis if all necessary conditions are met or refuting it otherwise.
This goal-driven method excels in scenarios where the aim is to assess the veracity of a specific contention, weaving through the tapestry of data to pinpoint supporting evidence.
Conflict Resolution: Harmonizing Competing Rules
When multiple rules vie for application, inference engines must employ conflict resolution strategies to decide which rule to prioritize. Conflict resolution is a critical aspect of reasoning that involves:
Identifying Conflicts: Detecting when more than one rule can apply to the same set of facts.
Applying Heuristics: Using predefined criteria, such as rule specificity or recency, to determine rule precedence.
Rule Execution: Selecting and executing the most appropriate rule based on the chosen conflict resolution strategy.
The determination of which rule to execute first is not arbitrary but a calculated decision that significantly affects the engine's inference path.
The detailed strategies of forward and backward chaining, as well as the nuanced techniques for conflict resolution, are well-documented in technical literature, including ScienceDirect and in the comprehensive documentation from Drools. These resources further elucidate the intricate mechanisms that inference engines employ to simulate human-like reasoning, underscoring their indispensable role in the realm of AI-driven operations.
Examples of Inference Engines
Vehicle Image Search Engine (VISE)
The realm of artificial intelligence is not just confined to theoretical constructs; it manifests in practical applications that deeply impact our daily life. A quintessential example of this is the Vehicle Image Search Engine (VISE), a collaborative creation by the University of Toronto and Northeastern University researchers. VISE harnesses an inference engine to sift through traffic camera data and pinpoint the location of vehicles, a tool that could revolutionize the efficiency of urban traffic management and law enforcement:
Real-World Application: VISE assists in monitoring traffic, locating missing vehicles, and potentially aiding in search for lost individuals.
Data Processing: Utilizing a region-based fully convolutional network (RFCN) for object detection and a ResNet-50-based CNN model, VISE analyzes traffic camera footage to extract vehicle features.
Speed and Precision: The system's backend, optimized for high-speed inference, processes images using GPUs in fractions of a second, thanks to the implementation of NVIDIA's TensorRT, a high-performance neural network inference optimizer and runtime engine.
NVIDIA's Deep Learning and AI Integration
NVIDIA, a powerhouse in the field of deep learning and AI, has seamlessly integrated inference engines within its frameworks. The NVIDIA Developer blog details how these engines are not only instrumental in AI model training but also play a vital role in the inference phase:
CUDA and TensorRT: NVIDIA employs CUDA and TensorRT Execution Providers in ONNX Runtime, optimizing for NVIDIA hardware and enabling the use of hardware-specific features like Tensor Cores across various platforms.
Enhanced Performance: This integration ensures optimal performance and access to cutting-edge hardware features, such as FP8 precision and the transformer engine in the NVIDIA Ada Lovelace architecture.
Amazon's Serverless Innovations
TechCrunch reports on how Amazon has embraced inference engines in its serverless offerings, exemplifying their utility in cloud computing and machine learning. Amazon Aurora Serverless V2 and SageMaker Serverless Inference embody this integration:
Amazon Aurora Serverless V2: A serverless database service that scales up and down with unprecedented speed and granularity, using inference engines to optimize database management and cost-efficiency.
SageMaker Serverless Inference: Offers a pay-as-you-go service for deploying machine learning models, with the inference engine playing a pivotal role in model deployment and execution, catering to models that require different latency and throughput needs.
These instances highlight the versatility and transformative potential of inference engines. From enabling the swift location of vehicles using traffic camera data to optimizing database scaling and machine learning model deployment, inference engines stand at the forefront of technological innovation, driving the progression of AI into ever more practical and impactful domains.
Use Cases of Inference Engines
Healthcare: Predictive Analytics
The healthcare industry has been profoundly transformed by the implementation of inference engines. Predictive analytics, a branch of advanced analytics, relies heavily on these engines to analyze historical and real-time data to make predictions about future events. Inference engines sift through vast amounts of patient data, identifying patterns that may indicate an increased risk of certain diseases or medical conditions. This enables healthcare providers to offer preventative measures or tailored treatment plans, thus improving patient outcomes and reducing costs. For instance, an inference engine might analyze a patient's electronic health records to predict the likelihood of a future hospital readmission, allowing healthcare providers to intervene proactively.
E-Commerce: Personalized Recommendations
E-commerce platforms utilize inference engines to create personalized shopping experiences. By analyzing past purchase history and browsing behavior, inference engines generate individualized product recommendations, enhancing customer satisfaction and increasing sales. A user's interaction with these recommendations further refines the inference engine's understanding of their preferences, leading to an increasingly tailored shopping experience. Amazon's recommendation system is a prime example of this application, where the inference engine underpinning the system analyzes millions of interactions to suggest products that a customer is likely to purchase.
Smart Home Devices: Automated Decision-Making
Smart home devices equipped with inference engines can make autonomous decisions based on the data they gather. Whether it's adjusting the thermostat or managing the lights, these engines process the homeowner's habits and preferences to make decisions that optimize for comfort and energy efficiency. By continuously learning and adapting, the inference engine can anticipate the homeowner's needs, providing a seamless and intuitive smart home experience.
Cybersecurity: Anomaly Detection
In the realm of cybersecurity, inference engines are indispensable for detecting anomalies that could indicate security breaches. These engines constantly monitor network traffic and user behavior, looking for deviations from established patterns that signal potential threats. Upon detection, the system can alert security professionals or initiate automated countermeasures to thwart the attack. The rapid and accurate detection capabilities of inference engines significantly enhance the security posture of organizations, reducing the risk of data breaches and other malicious activities.
Serverless Computing Environments: AWS's SageMaker Serverless Inference
Serverless computing environments, such as AWS's SageMaker Serverless Inference, showcase the adaptability of inference engines. These environments allow for the deployment of machine learning models without the need to manage the underlying infrastructure. The inference engine in a serverless setup handles the execution of the model, scaling resources up or down based on the demand, ensuring cost-effectiveness and eliminating the need for constant monitoring. Additionally, the serverless approach mitigates the risk of inference attacks, where attackers attempt to extract sensitive data by observing the output of machine learning models. SageMaker Serverless Inference provides a robust, secure environment for running inference tasks, protecting against such threats.
Aviation: Enhancing Efficiency and Precision
The aviation sector, as detailed in the Security InfoWatch article, benefits significantly from the precision and efficiency provided by inference engines. Real-time data analysis from aircraft sensors can predict maintenance needs, allowing airlines to perform proactive maintenance and avoid costly delays. For example, by analyzing data from jet engines in-flight, companies like Boeing and General Electric have been able to notify airlines of service requirements before a plane lands. This predictive maintenance ensures the aircraft operates at peak efficiency, saving fuel and extending the life of the engines while also enhancing passenger safety. The use of inference engines in aviation is a testament to their capacity to process complex data streams and deliver actionable insights in critical, time-sensitive contexts.
In each of these domains, inference engines serve as the unseen intellect, processing data and making decisions that subtly shape our interactions with technology. From enhancing patient care to personalizing online shopping, from securing our data to ensuring the planes we board are in top condition, inference engines work tirelessly behind the scenes. They are the unsung heroes of the AI revolution, driving forward innovations that make our lives safer, easier, and more connected.
Implementing an Inference Engine
When embarking on the implementation of an inference engine, one traverses a path that is as strategic as it is technical. The journey begins with the selection of the right knowledge representation, a decision that sets the stage for how effectively the engine will interpret and process information. Delving deeper, one must carefully choose an inference technique that complements the system's goals, whether it's forward chaining for a proactive stance or backward chaining for a confirmatory approach. The integration of the engine within an existing ecosystem demands meticulous planning and execution to ensure seamless functionality.
Knowledge Representation
Selecting the Right Format: The way knowledge is represented within the system dictates the engine's ability to reason. Whether opting for semantic networks, frames, or rules, the representation must align with the type of data and the desired inferences.
Consistency and Scalability: Ensuring that the chosen representation can maintain consistency as the knowledge base grows is paramount. Scalability allows the system to evolve and accommodate an expanding horizon of information.
Interoperability: In a world where systems often need to communicate, selecting a knowledge representation that promotes interoperability can greatly enhance the utility of the inference engine across different platforms and applications.
Inference Technique
Forward vs. Backward Chaining: The choice between a data-driven (forward chaining) or a goal-driven (backward chaining) approach hinges on the specific requirements of the application. Each technique offers unique advantages that must be weighed against the system's objectives.
Conflict Resolution: When multiple rules are applicable, devising a robust conflict resolution strategy ensures the engine selects the most appropriate rule to execute, thereby optimizing the decision-making process.
System Integration
Compatibility: Integrating an inference engine with existing systems requires careful consideration of compatibility to avoid disruptions and ensure that the engine can access the necessary data.
Performance Tuning: Fine-tuning the engine's performance to work efficiently within the constraints of the existing infrastructure is crucial to prevent bottlenecks and maintain optimal operation.
Development and Security
Python for Custom Engines: Python emerges as a preferred language for developing custom inference engines due to its rich ecosystem of libraries and its prominence in AI and machine learning communities.
Open-Source Tools: Open-source tools offer a pathway to build robust and secure systems while providing the transparency needed to identify and mitigate potential data leakage risks, as exemplified by research on AI system vulnerabilities.
Continuous Learning and Adaptation
Machine Learning Integration: Integrating machine learning methods enables the inference engine to adapt and learn from new data, ensuring its conclusions remain relevant and accurate over time.
Feedback Loops: Implementing feedback loops allows the engine to refine its reasoning capabilities, leveraging user interactions and outcomes to enhance future inferences.
Performance Optimization
TensorRT and ONNX Runtime: Advanced tools like TensorRT and ONNX Runtime play a critical role in optimizing inference engine performance, particularly in NVIDIA-based systems where they harness hardware-specific features to deliver high-speed inference capabilities.
Leveraging Hardware Acceleration: Utilizing hardware acceleration features, such as those provided by NVIDIA GPUs, can significantly improve the inference speed and efficiency, paving the way for real-time AI applications.
Each step in implementing an inference engine is a deliberate choice that influences the overall effectiveness and efficiency of the AI system. From the initial selection of knowledge representation to the ongoing process of learning and adaptation, the goal remains to build an engine that is not only intelligent but also harmonious with the systems it enhances. Achieving this synergy is the hallmark of a well-implemented inference engine, one that stands ready to meet the demands of an ever-evolving digital landscape.