Perceptron
A simple single-layer neural network model that takes a linear combination of weighted inputs, passes it through an activation function, and outputs a prediction used for binary classification.
The Perceptron stands as a foundational algorithm in the realm of artificial intelligence, offering a first glimpse into the potential of computational models to mimic biological neural networks. Introduced by Frank Rosenblatt in 1958, the Perceptron was conceived at the Cornell Aeronautical Laboratory. Its development emerged from the aspiration to design machines that could automatically learn from experience, somewhat mirroring human cognitive processes.
The significance of Perceptrons in the annals of computational models cannot be overstated. At its core, a Perceptron is a binary classifier; it makes decisions based on the weighted sum of its input signals. While simple in its design, this algorithm revealed that complex computations could be decomposed into a series of linear operations.
The Perceptron is often considered the most basic unit when discussing neural networks. Just as a biological neuron receives signals, processes them, and produces an output, so does a Perceptron. While individual Perceptrons are limited to linearly separable tasks, their true power becomes evident when they are interconnected in multi-layer architectures. This structure, known as the Multi-layer Perceptron (MLP), forms the basis of many modern neural networks and was a precursor to more advanced deep learning models. The Perceptron’s foundational role in laying the groundwork for subsequent breakthroughs in artificial neural network architectures is undeniable in this context.
The Basics
At its most fundamental level, the Perceptron is a type of artificial neuron, or a mathematical construct, inspired by biological neurons. Its primary purpose is to classify its inputs into one of two possible outcomes: often referred to as 0 or 1, negative or positive, or any binary classification. Its foundational nature in neural network research has made it a staple topic for those entering the machine learning and artificial intelligence field.
A Perceptron is a linear binary classifier that operates on a set of input values to produce a single binary output. It receives multiple inputs, processes them, and produces a single output. The idea is to weigh the importance of each input, sum them up, and then decide the output based on this summation.
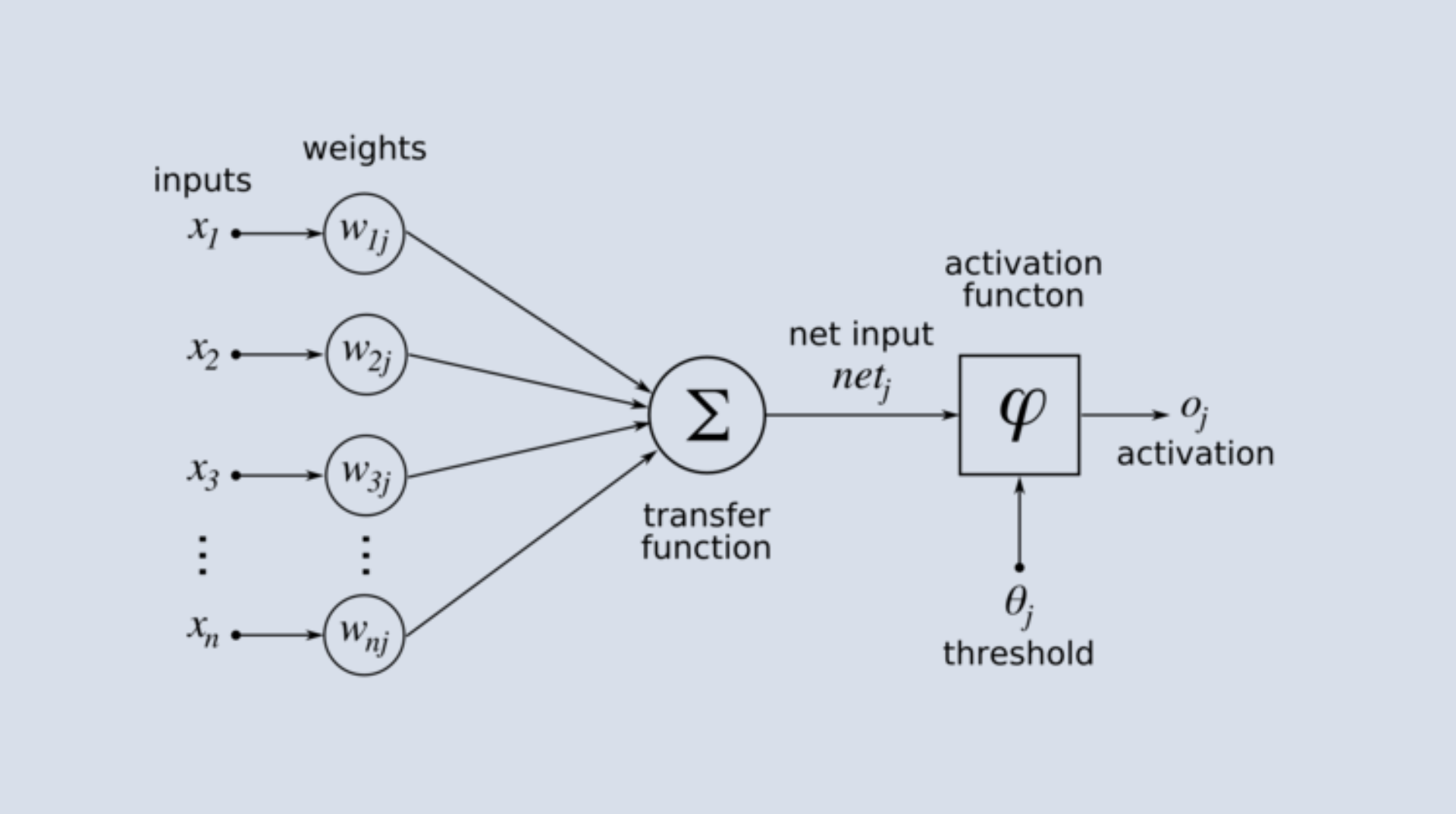
Diagram of Rosenblatt's perceptron.
Structure
The architecture of a Perceptron is relatively straightforward, consisting of:
Inputs (x1, x2, … xn): These are analogous to the dendrites of a biological neuron. Each input corresponds to a feature of the data being processed.
Weights (w1, w2, … wn): Weights are values that control the influence or importance of their corresponding inputs. They are the parameters adjusted during the learning process to optimize classification decisions.
Bias (b): The bias is an additional parameter that allows the Perceptron to shift its decision boundary. In essence, while weights determine the orientation of the decision boundary, the bias determines its position.
Activation Function: After the inputs are weighted and summed with the bias, the result passes through an activation function that produces the final output. A basic Perceptron's most common activation function is the step function, which outputs 1 if the summed value exceeds a threshold and 0 otherwise.
Function: Making Decisions or Classifications
The operational mechanism of a Perceptron can be visualized as a series of mathematical steps:
Weighted Sum: The inputs are multiplied by their corresponding weights, and the results are summed together along with the bias. Mathematically, this can be represented as:
[ \text{Sum} = w1x1 + w2x2 + … + wn*xn + b ]Apply Activation Function: The weighted sum is then passed through the activation function. If using a step function as the activation function:
[ \text{Output} =
\begin{cases}
1 & \text{if } \text{Sum} > \text{threshold} \
0 & \text{otherwise}
\end{cases} ]
By adjusting the weights and bias through iterative learning (usually through a process called the Perceptron learning rule), the Perceptron refines its decision-making capabilities, improving its classification accuracy on training data. The objective is for the Perceptron to learn the optimal weights and biases to correctly classify as many instances as possible from its training set.
While the single-layer Perceptron has its limitations, most notably its inability to solve non-linearly separable problems, its conceptual framework paved the way for more complex neural network architectures, including multi-layer networks, which can handle a broader range of computational challenges.
Evolution from Perceptrons to Neural Networks
The journey from Perceptrons to modern neural networks is a tale of evolving complexity, where each step in the evolution sought to overcome the limitations of the previous one. Through these stages, the ambition was always clear: to create computational models capable of emulating the intricate processes of the human brain and achieving remarkable feats in various domains, including Natural Language Processing (NLP).
Limitations of Single-layer Perceptrons
The Perceptron, during its initial stages, was celebrated as a transformative advancement in computational models. Its ability to linearly classify made it instrumental in a variety of domains. However, as research deepened, some inherent constraints of single-layer Perceptrons emerged, limiting their broader applicability.
A particularly challenging issue was the XOR (exclusive OR) problem. At its core, the XOR function delivers a true result when exactly one of its two binary inputs is true. When plotted, the XOR challenge isn’t linearly separable—meaning, it’s impossible to delineate the positive and negative instances with a singular straight line. Since single-layer Perceptrons fundamentally rely on constructing straight decision boundaries, they inevitably faltered with the XOR conundrum.
This XOR limitation was indicative of a broader concern: the principle of linear separability. Single-layer Perceptrons inherently thrive when managing datasets that are linearly separable. To put it simply, these datasets can be divided unambiguously with a straight line in a two-dimensional setting or a flat plane in three dimensions. Yet, the complexity of real-world scenarios, including many tasks in Natural Language Processing (NLP), often presents non-linear data. These non-linear intricacies surpass the capacity of a mere Perceptron, signifying the need for advanced models to grasp the nuanced patterns embedded within the data.
Introduction to Multi-layer Perceptrons (MLP)
The Multi-layer Perceptron (MLP) emerged as a response to the challenges faced by single-layer Perceptrons. Designed with greater complexity, the MLP offers enhanced computational abilities compared to its predecessor.
In terms of structure, the MLP is notably more intricate. It includes an input layer for initial data reception, one or more ‘hidden’ layers for data processing, and an output layer for producing the final outcome. Each layer contains multiple Perceptrons or neurons, lending the MLP its characteristic depth.
The function of an MLP involves a systematic progression of data through its layers. Data starts at the input layer and is transformed sequentially across layers. Each neuron in a given layer processes outputs from the preceding layer’s neurons and passes its result to the subsequent layer, allowing for continuous data transformation.
A vital advantage of the MLP is its ability to approximate diverse continuous functions when equipped with adequate neurons and layers. The hidden layers introduce the capability to model complex decision boundaries, enabling the MLP to tackle non-linear problems that single-layer Perceptrons find challenging.
Transition to Deep Neural Networks and Relevance in NLP
The journey of neural networks has been one of continuous evolution, spurred by both burgeoning computational prowess and algorithmic refinements. The multifaceted MLPs, with their modest hidden layers, paved the way for the emergence of Deep Neural Networks (DNNs). The essence of “deep” in DNNs encapsulates the profound depth, denoted by the multitude of hidden layers, empowering these networks to internalize and represent intricately complex functions.
DNNs are marvels not just in depth but also in their expansive breadth, making them adept at deciphering and assimilating the nuanced patterns strewn across vast data landscapes. This capability becomes indispensable when venturing into the realm of Natural Language Processing (NLP). Here, the labyrinthine intricacies of language, encompassing subtle nuances, overarching context, and profound semantics, demand a computational architecture that’s both deep and versatile.
One of the transformative innovations brought to the fore by deep learning in NLP is the concept of word embeddings. This paradigm envisages words as vectors situated in high-dimensional spaces. Unlike mere numerical representations, these embeddings are imbued with the capability to capture the semantic fabric that binds words. This imbues words with relational context and catalyzes advancements in pivotal NLP undertakings, such as machine translation and sentiment analysis.
Delving deeper into the NLP architectures, we witness the advent of specialized network designs tailored for linguistic tasks. For instance, recurrent Neural Networks (RNNs) emerged as an answer to language’s inherent sequentiality, ensuring words are not perceived in isolation but as a continuum. The transformative baton was later passed to Transformer architectures. These models, with their emphasis on attention mechanisms, became the vanguard for tasks demanding intricate interplay, like language translation.
In tracing back to the inception of the Perceptron, it becomes evident that modern neural networks, especially those sculpted for NLP, weren’t birthed overnight. Instead, it’s a monumental edifice, erected layer upon layer, innovation meticulously stacked atop innovation. This cumulative effort has made it conceivable for machines to grapple with language and, in specific domains, to rival or even eclipse human linguistic dexterity.
NLP Tasks with Perceptrons and MLPs
Natural Language Processing comprises many tasks that enable machines to understand, interpret, and generate human language. As computational models evolved, early neural architectures like Perceptrons and their multi-layered counterparts, MLPs, began to be applied to several foundational NLP tasks, setting the stage for more advanced models.
Early Text Classification Tasks
Text classification is a foundational task in Natural Language Processing (NLP), where the primary objective is to assign textual data into predefined categories based on its content. This technique has been employed in various applications, from discerning spam emails to sorting news articles by their relevant topics.
In the nascent stages of NLP, single-layer Perceptrons played a pivotal role, especially in binary text classification scenarios. Their architecture was apt for making binary decisions, such as differentiating a genuine email from a spam one. The mechanism involved representing each word or feature of the text as an input to the Perceptron. As the model underwent training, it continuously adjusted its weights to improve the distinction between the two classes, thereby optimizing the classification process.
However, as textual data’s complexity grew and the requirement to classify texts into multiple categories became more evident, the Multi-layer Perceptrons (MLPs) gained prominence. Equipped with a multi-layered architecture and the capacity to incorporate non-linear activation functions, MLPs showcased the ability to detect intricate patterns within texts. Such capabilities made them especially potent for multifaceted tasks, such as sorting news articles into a range of topics based on their content.
Part-of-Speech Tagging
A cornerstone in the realm of NLP is the task of part-of-speech (POS) tagging. It involves assigning appropriate part-of-speech labels - be it a noun, verb, adjective, among others - to individual words within a sentence. The significance of POS tagging is immense as it serves as a precursor to more advanced NLP tasks, including parsing and named entity recognition.
For Perceptrons and MLPs to contribute to POS tagging, a crucial step involved the conversion of words and their associated context into feature vectors. These features encapsulated various elements of the word, ranging from its inherent meaning, suffixes, prefixes, to the contextual words surrounding it. In some sophisticated models, even previously predicted POS tags were considered as features.
The training phase saw Perceptrons being fed labeled datasets, where they adjusted their weights to align with the provided POS tags. However, MLPs, boasting their ability to interpret non-linear patterns, had an edge. Their structure allowed them to factor in intricate contextual cues, offering a more nuanced understanding of the text. Consequently, in many instances, MLPs outperformed single-layer Perceptrons in terms of accuracy and prediction capabilities.
Basic Sentiment Analysis
Sentiment analysis stands as a cornerstone of Natural Language Processing, functioning to discern the underlying sentiment or emotional tone enveloped within textual data. Its applications are varied and encompass domains such as gauging public sentiments on contemporary issues, vigilantly monitoring the reputation of brands in real-time, and deriving insights from customer feedback.
In the initial phases of sentiment analysis, single-layer Perceptrons were predominantly deployed, especially when the analysis was binary – typically distinguishing between positive and negative sentiments. Given a labeled dataset comprising both positive and negative reviews, a Perceptron would embark on its training journey. The objective was clear: proficiently categorizing incoming reviews as positive or negative. The model would extract features from the text, focusing on indicators like specific words tinged with sentiment, the frequency of particular terms, or even seemingly unrelated factors like the length of the review. Over time and with adequate training, the Perceptron would fine-tune its weights, enhancing its ability to discern sentiments in unseen data accurately.
However, as the domain of sentiment analysis evolved, it became evident that sentiments were not strictly binary. Textual data could convey a spectrum of emotions, from starkly positive or negative to neutral, or even a blend of multiple sentiments. Catering to this complexity required a more sophisticated model, ushering in the era of Multi-layer Perceptrons for sentiment analysis. MLPs, with their inherent ability to tackle multi-class problems, emerged as an apt choice for this refined level of sentiment analysis. These models would undergo training on datasets meticulously labeled with a multitude of sentiment classes. The MLP adjusted its weights through the training process, aiming to master the art of predicting a broad range of sentiments for fresh, unseen data. Their layered architecture and non-linear processing capabilities enabled them to capture the nuances in sentiment that a single-layer Perceptron might overlook.
Perceptrons and MLPs played crucial roles in the early days of neural-based NLP. While more advanced architectures have largely superseded them for many NLP tasks, their foundational contributions to the field’s progress are undeniable. Their ability to learn from data and make predictions, even if somewhat rudimentary compared to today’s standards, marked the beginning of a shift from rule-based NLP systems to data-driven, neural ones, paving the way for the contemporary NLP landscape we’re familiar with today.
Large Language Models and Their Connection to Perceptrons
A Large Language Model is a type of neural network architecture specifically trained on vast amounts of textual data to understand and generate human-like text. Over time, as computational resources and data availability expanded, neural network architectures grew in complexity, leading to the development of these LLMs. Within their underlying architecture, the foundational principles of Perceptrons are still present and play a crucial role in modeling intricate patterns of language.
Structure and Operation of LLMs
Transitioning from the foundational Perceptrons to the intricate LLMs is not merely a shift in scale. Still, it represents a remarkable expansion both in terms of depth, characterized by the number of layers, and breadth, denoted by the number of neurons or computational units housed within each layer. These deep learning strata's profound depth enables LLMs to adeptly discern, learn, and emulate the sophisticated patterns, subtle nuances, and multifaceted relationships embedded within the colossal text corpora they’re honed on.
The input and embedding layers are at the onset of an LLM’s processing pipeline. Here, raw textual data undergoes a transformative journey, much like in the predecessors such as MLPs, but with heightened finesse. Fundamental linguistic units, whether they be singular words, composite phrases, or even atomic characters, undergo a metamorphosis into vectors situated within high-dimensional spaces. These vectors are meticulously crafted to encapsulate the inherent semantic essence of their corresponding linguistic constituents.
Diving deeper into the architecture reveals the myriad hidden layers that form the core computational machinery of LLMs. These layers, staggering in their scale, can encompass anywhere from millions to a staggering billions of parameters. Contemporary LLMs predominantly rely on transformer-based architectures in these realms, wherein the initial embeddings are channeled through a labyrinth of computational transformations and intricate processing stages, each refining and reshaping the data further.
Concluding the LLM’s intricate processing is the output layer. This terminal stage translates the cumulative understanding and processing of the model into tangible outcomes. The nature of this output is malleable and contingent on the task at hand. It might manifest as an anticipated subsequent word in scenarios of text generation, emerge as a categorical label for endeavors like sentiment analysis, or take any form that aligns with the specific objective being pursued.
The Role of Numerous Interconnected Perceptrons in Modeling Language
The architectural intricacy of contemporary LLMs far surpasses that of the pioneering Perceptrons. However, underlying this complexity, the foundational ethos needs to be more balanced. Central to these deep structures is a vast network of interconnected Perceptrons or neurons, each contributing in unison to the broader linguistic objectives of the model.
Every neuron within an LLM operates as a vital computational entity. It intakes a series of inputs, undergoes processing influenced by designated weights and biases reminiscent of the original Perceptrons, and culminates in an output. This resultant value then serves as the input for subsequent neurons, establishing a structured, layered flow of information through the network.
The ability of LLMs to identify and emulate nuanced linguistic constructs is partly due to their adeptness at integrating non-linearities. Mirroring the strategy of Multi-layer Perceptrons (MLPs), which harnessed activation functions to infuse non-linearity into their computations, LLMs similarly employ non-linear activations. This ensures they can recognize and represent the myriad patterns and interdependencies that pervade language.
A distinguishing feature of LLMs is their prowess in parallel information processing. The vast lattice of interconnected Perceptrons facilitates simultaneous data processing. Individual neurons collaborate seamlessly, each attuned to discern specific linguistic features or patterns. Their combined efforts culminated in a comprehensive, holistic grasp of the linguistic content at hand.
LLMs are a testament to the evolutionary journey that commenced with the humble Perceptron. While rooted in similar foundational principles, the scale and sophistication they’ve achieved permit an unparalleled depth of language understanding. This progression, from the rudimentary Perceptron to the sophisticated LLM, highlights the immense potential of iterative advancements and the transformative capabilities of neural architectures in emulating and generating human linguistic expressions.
Conclusion
The journey of Perceptrons from simple linear classifiers to their foundational role in Large Language Models (LLMs) reveals the transformative evolution of Natural Language Processing (NLP). From handling rudimentary tasks like text classification and part-of-speech tagging, we now have models that excel in complex challenges such as translation, question-answering, and summarization. The depth and sophistication of LLMs have undoubtedly elevated the capabilities of NLP systems. Yet, as with any technological advance, they come with their own set of challenges, from data and computational demands to concerns about bias, fairness, and overfitting. Addressing these challenges is as much about technological innovation as it is about ethical deliberation. As we forge ahead, it’s essential to approach the potential and pitfalls of LLMs with a balanced perspective, ensuring that advancements in NLP align with the broader goals of utility, inclusivity, and responsibility.