Adversarial Machine Learning
At its core, Adversarial Machine Learning (AML) involves crafting inputs specifically designed to deceive machine learning models—inputs that appear benign to human observers but wreak havoc on the algorithms that underpin AI systems. This dualistic nature of AML makes it a double-edged sword...
Have you ever pondered the delicate balance between technological innovation and security? As we venture deeper into the realm of artificial intelligence (AI), a new frontier emerges where cybersecurity intersects with AI—this is the domain of adversarial machine learning (AML). With AI systems becoming ubiquitous across various industries, from healthcare to finance, the urgency to address the Achilles' heel of these systems is paramount. AML exposes and exploits the vulnerabilities inherent in machine learning models, which could have profound implications for the safety and reliability of AI applications.
What is Adversarial Machine Learning?
Adversarial Machine Learning (AML) is a sophisticated field where cybersecurity and artificial intelligence converge, and understanding its nuances is crucial in a world increasingly driven by AI. At its core, AML involves crafting inputs specifically designed to deceive machine learning models—inputs that appear benign to human observers but wreak havoc on the algorithms that underpin AI systems. This dualistic nature of AML makes it a double-edged sword; it is a weapon in the arsenal of those looking to exploit AI vulnerabilities, as well as a shield for researchers working diligently to enhance AI's robustness.
The concept of 'data poisoning' is particularly illustrative of the offensive capabilities of AML. It's a strategy where attackers inject corrupted data into the machine learning pipeline, causing the model to learn incorrect patterns and make erroneous predictions. The LinkedIn article on adversarial attacks highlights this tactic as a significant threat to AI/ML models. This insidious form of attack can have far-reaching consequences, potentially leading to the failure of systems that rely on accurate machine learning models, such as autonomous vehicles or financial fraud detection systems.
In the broader scope of AI security, understanding and mitigating the risks posed by AML is paramount. AML is not just about the attacks themselves but also encompasses the strategies and techniques developed to defend against these attacks. It is a continuous battle of wits between attackers looking to find and exploit new vulnerabilities and defenders working to patch existing ones and anticipate potential future threats.
AML plays a vital role in the proactive discovery of AI vulnerabilities. Before malicious actors have a chance to exploit a weakness, researchers can use AML techniques to identify and address these vulnerabilities, thereby fortifying the system against potential attacks. This preemptive approach is critical in maintaining the integrity and trustworthiness of AI systems.
Ultimately, the field of adversarial machine learning represents a frontier that is as fascinating as it is unsettling. It is a realm where the pursuit of stronger, more reliable AI systems must account for the ingenuity of those who would undermine them. As we deploy AI in more critical applications, the importance of AML and the need for robust defense mechanisms against such threats cannot be overstated.
How Adversarial Machine Learning Works
The intricacies of adversarial machine learning (AML) unveil a complex chess game between model robustness and exploitation. The crux lies in adversarial examples: specially crafted inputs that look normal to human eyes yet cause AI models to falter. These examples aren't haphazard guesses but the result of meticulous engineering designed to probe and exploit the weaknesses of machine learning models.
Crafting Adversarial Examples
One method of strategic generation of adversarial noise is to create adversarial examples. It's a process of adding carefully calculated distortions to the original data, which can lead to misclassification by the model. These perturbations are minute, often imperceptible to humans, but they induce significant misinterpretations by AI systems. The attacker's knowledge of the model's architecture and training data can greatly influence the effectiveness of these perturbations.
For example, there exists a dataset known as SQuAD, which contains thousands of short articles and stories followed by multiple-choice questions about those articles and stories. You can think of it like the “Reading” section on the SAT, ACT, LSAT, or another standardized test.
When testing an LLM on its reading comprehension skills, one way to adversarially impact the data is to write unanswerable questions—that is, questions about articles that are not contained within the dataset. You might even ask the LLM “When is my birthday?” The answer choices to these questions should include an “I don’t know” option.
A truly robust LLM would select the “I don’t know” option. A trickable LLM would simply guess.
Adversarial Testing Workflow
Systematic evaluation, as exemplified by Google's adversarial testing workflow, is paramount for understanding how AI models react to malicious inputs. This testing is not a one-off event but an ongoing process that scrutinizes the model's behavior under duress, revealing potential vulnerabilities that could be exploited in real-world scenarios.
Understanding Decision Boundaries
The boundary attack methodology emphasizes the importance of understanding model decision boundaries. These are the zones where the AI's certainty about data classification wavers, making it ripe for manipulation through adversarial inputs. By pushing inputs towards these boundaries in a controlled manner, researchers can evaluate the resilience of models and improve their defenses.
Game Theory in AML
Game theory, as outlined in the AAAI journal, models the interactions between attackers and defenders in AML. It sets the stage for a strategic back-and-forth where each side's moves and countermoves are analyzed for optimal play. The defenders' goal is to minimize potential losses by anticipating and neutralizing the attackers' strategies, while attackers aim to find the most effective way to cause misclassification without detection.
The dance between adversarial attacks and defenses is one of perpetual motion; as long as AI systems remain integral to our digital ecosystem, this interplay will continue to evolve. Understanding the workings of adversarial machine learning is not just an academic exercise—it's a necessary part of ensuring that our reliance on AI doesn't become our Achilles' heel.
Types of Adversarial Machine Learning Attacks
In the realm of adversarial machine learning (AML), attacks come in various forms, each with its unique approach to deceiving and undermining AI systems. From subtle perturbations to complex inference strategies, the landscape of AML is fraught with challenges that test the mettle of modern AI defenses.
Poisoning Attacks
These attacks involve injecting malicious data into the model's training set, effectively "poisoning" the well from which the AI draws its learning. By doing so, attackers can skew the model's predictions or decision-making processes from the outset. The goal might be to create a backdoor that can be exploited later or to degrade the overall performance of the model.
Evasion Attacks
With evasion attacks, adversaries aim to fool a machine learning model at the inference stage. They craft input data that is likely to be misclassified. This type of attack does not tamper with the model directly; instead, it exploits the model's vulnerabilities post-training, during the time of prediction. The CSO Online article underscores the stealthy nature of these attacks, as they carefully navigate around the learned decision boundaries without triggering any alarms.
Extraction Attacks
Here, the attacker's objective is to reverse-engineer the model in order to extract valuable information about its structure or the data it was trained on. This could lead to a full-blown replication of the AI system, which could be used for unauthorized purposes or to strengthen further attacks against the model.
Inference Attacks
Inference attacks do not seek to alter the model's behavior but to glean sensitive information from it. These attacks exploit the model's predictions to make inferences about the original dataset, potentially exposing private data or insights that were not intended for release.
Perturbation, Fabrication, and Impersonation
Perturbation: This refers to the addition of carefully designed noise to an input, causing the model to misclassify it. As detailed in research papers hosted on arXiv, these perturbations are often imperceptible to humans but lead to significant errors in machine perception.
Fabrication: This attack fabricates new synthetic data points designed to deceive the AI model. Unlike perturbations that tweak existing data, fabrications are entirely new creations intended to exploit specific weaknesses in the data processing pipeline.
Impersonation: In this scenario, the adversarial input mimics a legitimate one, tricking the system into granting access or privileges it should not. It's akin to a digital form of identity theft, where the AI is deceived into recognizing something or someone as trusted when it is not.
White-Box vs. Black-Box Attacks
The knowledge about the target model distinguishes white-box attacks from black-box attacks. In a white-box scenario, attackers have full visibility into the model, including its architecture, parameters, and training data. They can craft bespoke inputs that exploit the model's specific configurations.
Conversely, black-box attacks operate without inside knowledge of the model. Attackers might only see the outputs or have to make educated guesses about the underlying mechanics. The boundary attack, as relevant to black-box models, exemplifies this approach — it iteratively tests and tweaks the adversarial inputs based on the model's outputs, inching ever closer to a successful deception.
Human and Computer Vision Deception
The sophistication of adversarial attacks reaches a point where both human and computer vision can be fooled. Research on arXiv highlights cases where altered images are misclassified by machine learning models and misinterpreted by human observers. This convergence of deception underscores the nuanced and powerful nature of adversarial examples — they are not just a technical glitch in the matrix but a profound challenge to our trust in machine perception.
In navigating the adversarial landscape, one realizes the importance of constant vigilance and innovation in defense strategies. As AI continues to permeate various facets of life, understanding and mitigating adversarial attacks becomes not just a technical endeavor but a fundamental pillar in the architecture of trustworthy AI systems.
Note that these classic “tricks” in computer vision are what make CAPTCHAs so difficult for a machine. The images found on Captchas (like the ones seen below) are deliberately difficult for current computer vision AI, while humans—who are, in general, mentally robust—can answer them simply.
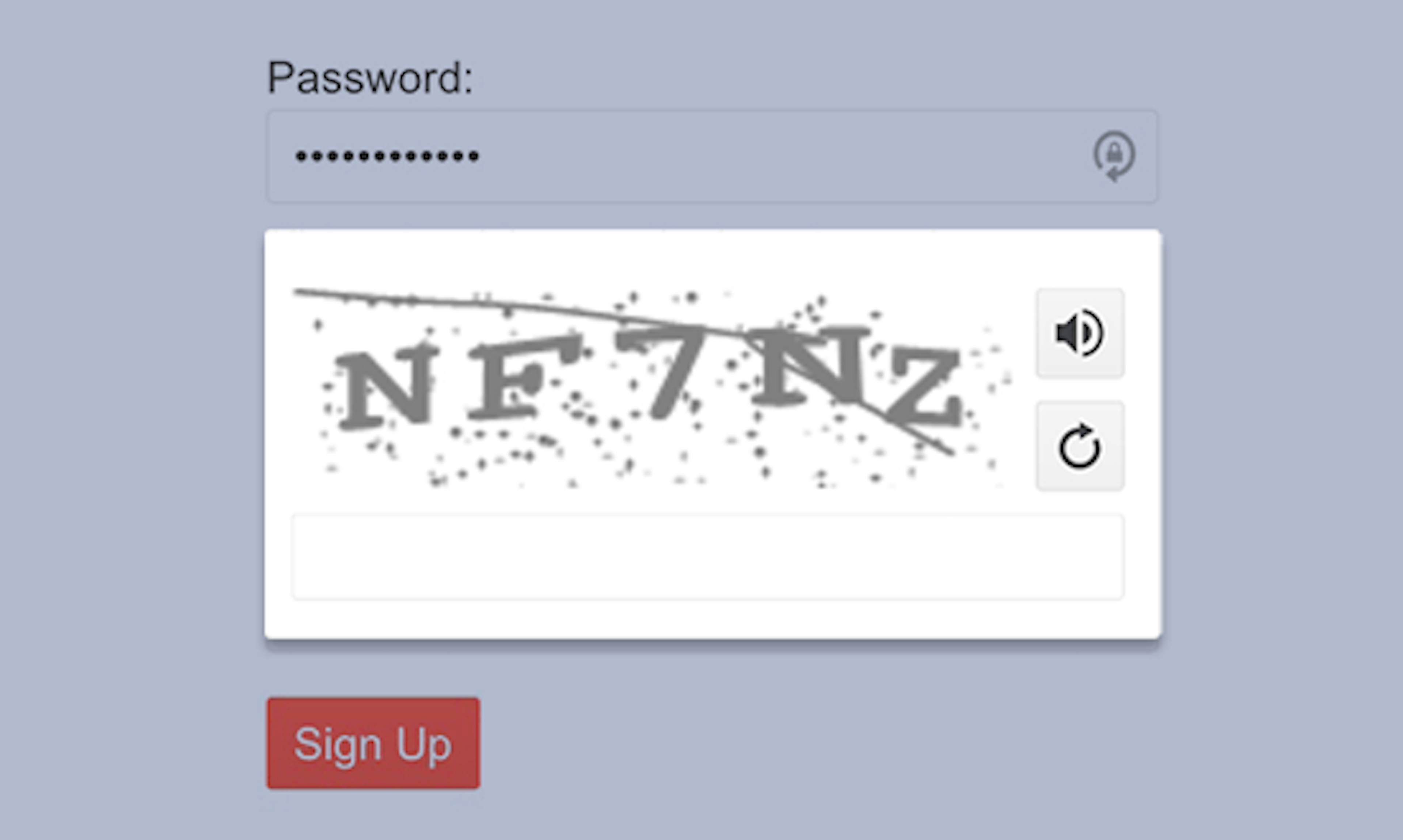
Examples of Adversarial Machine Learning Attacks
Adversarial machine learning is not a theoretical concern but a practical one, with real-life attacks demonstrating the vulnerability of AI systems. These attacks serve as a wake-up call to the potential havoc that can be wreaked when AI is deceived.
The Adversarial Stop Sign
An alarming instance of an adversarial attack was chronicled by OpenAI, where researchers manipulated a stop sign in such a way that an autonomous vehicle's image recognition system would interpret it as a yield sign or other non-stop signals. This type of attack could have dire consequences, especially when considering the reliance on AI for interpreting road signs in autonomous vehicles. The safety implications are profound: a misinterpreted signal could lead to accidents, underscoring the urgent necessity for resilient AI systems in the transportation sector.
Foolbox and 'Black Box' AI
The Foolbox tool, developed by researchers at Eberhard Karls University Tubingen, highlights the fragility of 'black box' AIs — systems where the internal workings are unknown to the attacker. Foolbox demonstrates the ability to create adversarial models that can trick these systems into incorrect classifications. The potential risks are significant as black box AIs are common in various industries, and the ability to deceive them without deep knowledge of their architecture opens a pandora's box of security concerns.
Audio Classification Under Siege
Researchers at the École de Technologie Supérieure have uncovered vulnerabilities in audio classification systems. Their work reveals how adversarial attacks can manipulate audio inputs in ways that are imperceptible to humans but cause AI models to make errors in classification. This type of attack could be used to, for instance, issue unauthorized commands to voice-controlled devices or falsify evidence in legal proceedings. The cross-domain impact of AML is evident here, indicating that any system reliant on audio inputs is at potential risk.
The examples mentioned here only scratch the surface of how adversarial machine learning can manifest in real-world scenarios. As AI systems become more integrated into critical aspects of society, from transportation to legal and security sectors, the need for advanced defense mechanisms against adversarial attacks becomes increasingly paramount. These attacks are not isolated incidents but indicators of a broader need for robust and secure AI.
Defending against Adversarial Machine Learning
The landscape of AI security requires a robust defense against adversarial machine learning (AML), where the stakes are high and the adversaries are inventive. Protecting AI systems from these attacks is not just about safeguarding data but also about ensuring the integrity and reliability of AI-driven decisions. Let's explore some of the advanced strategies and methodologies that are currently at the forefront of defending against these nuanced threats.
Adversarial Training
Adversarial training involves the intentional inclusion of adversarial examples during the training phase of machine learning models. The principle is straightforward: by exposing the model to a spectrum of adversarial tactics, it learns to recognize and resist them. This method not only strengthens the model's defenses but also expands its understanding of the data it processes. The adversarial training chapter from adversarial-ml-tutorial.org provides a comprehensive breakdown of how this technique effectively serves as a sparring session, toughening up models for the real-world challenges they face.
Defensive Distillation
Defensive distillation is another technique that enhances the resilience of AI systems. This process involves training a secondary model to generalize the predictions of the original model with a softer probability distribution. Essentially, the second model learns from the output of the first but in a way that is less sensitive to the perturbations that characterize adversarial attacks. By doing so, defensive distillation can mitigate the risk of adversarial examples leading to misclassification.
Robust Feature Learning
Turning to robust feature learning, this defense mechanism aims at capturing the essence of data in such a way that it is impervious to the slight but malicious alterations adversarial attacks are known for. Research from the École de Technologie Supérieure delves into this concept, particularly in the context of audio classification defense. By focusing on the underlying features that are less likely to be affected by adversarial noise, robust feature learning can form a core line of defense, enabling models to maintain performance even in the face of skilfully crafted attacks.
Anomaly Detection and Input Sanitization
Anomaly detection and input sanitization play crucial roles in preemptively identifying and neutralizing adversarial threats. Anomaly detection algorithms are the gatekeepers, constantly scanning for data points that deviate from the norm, which could indicate an adversarial attack in progress. Input sanitization, on the other hand, is the process of cleansing the data before it's fed into the model, ensuring that any potential threats are neutralized at the doorstep.
Debate on Current Defense Strategies
While these strategies represent the spearhead of defense against adversarial machine learning, they are not without their limitations. Adversarial training can be computationally expensive and may not cover all possible attack vectors. Defensive distillation, while innovative, may not always provide the desired level of protection against more sophisticated attacks. Robust feature learning is promising but still a developing field, where the nuances of what constitutes 'robustness' are actively being explored.
Ongoing research and development are critical in this cat-and-mouse game between attackers and defenders. The dynamism of AML ensures that defense strategies must evolve continuously to address emerging threats. Thus, the AI community remains vigilant, innovating tirelessly to protect the integrity of machine learning models and the systems they empower.