


Table of Contents
TL;DR
- Deepgram’s Voice Agent API provides a single, unified interface with two flexible paths: use our best-in-class stack (Nova-3 for speech-to-text, Aura-2 for text-to-speech, and supported LLMs), or bring your own LLM and TTS while retaining full orchestration and conversational control.
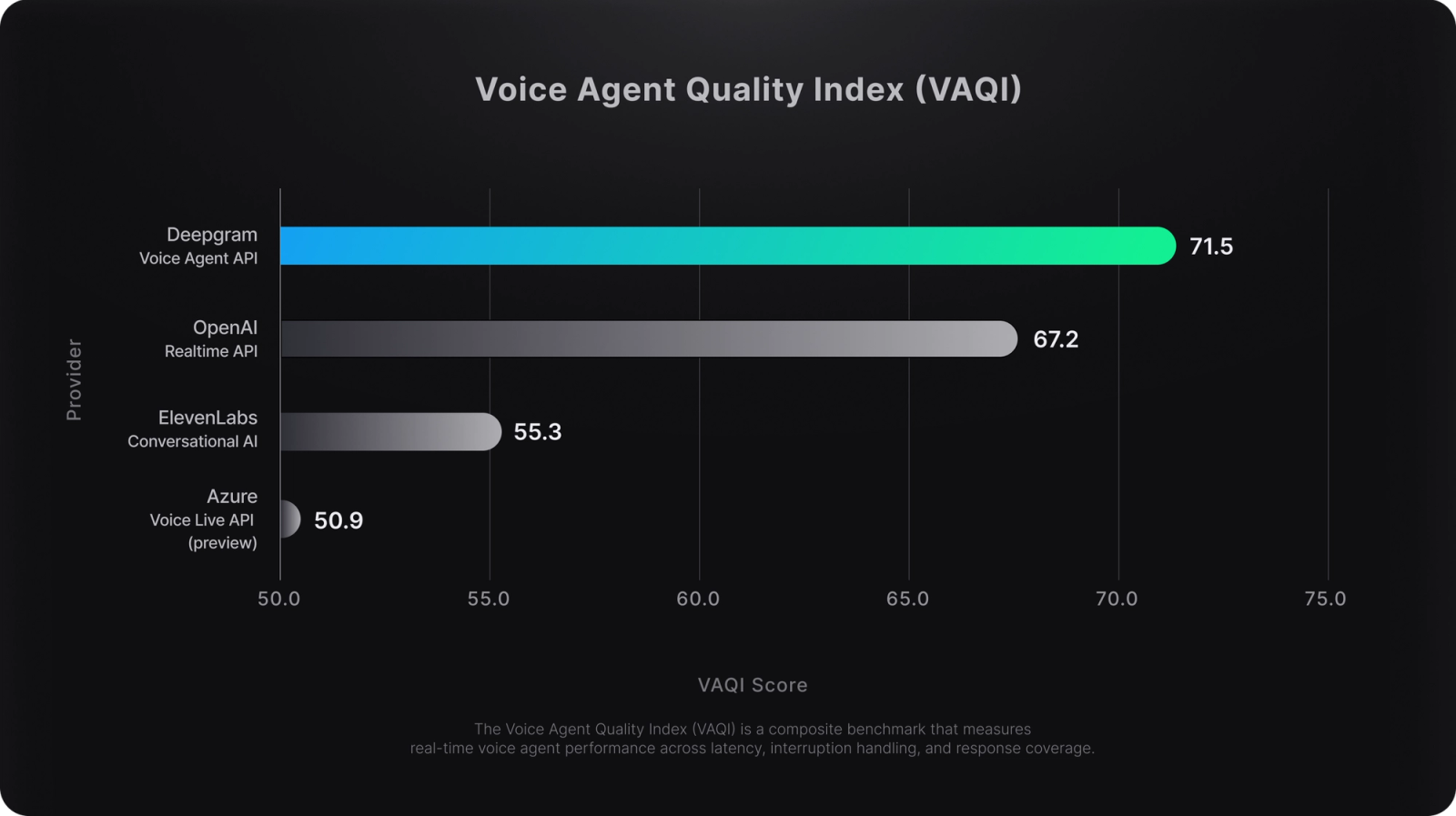
- Deepgram outperforms competitors in the Voice Agent Quality Index (VAQI), a composite benchmark that measures real-time voice agent performance across latency, interruption control, and response completeness.
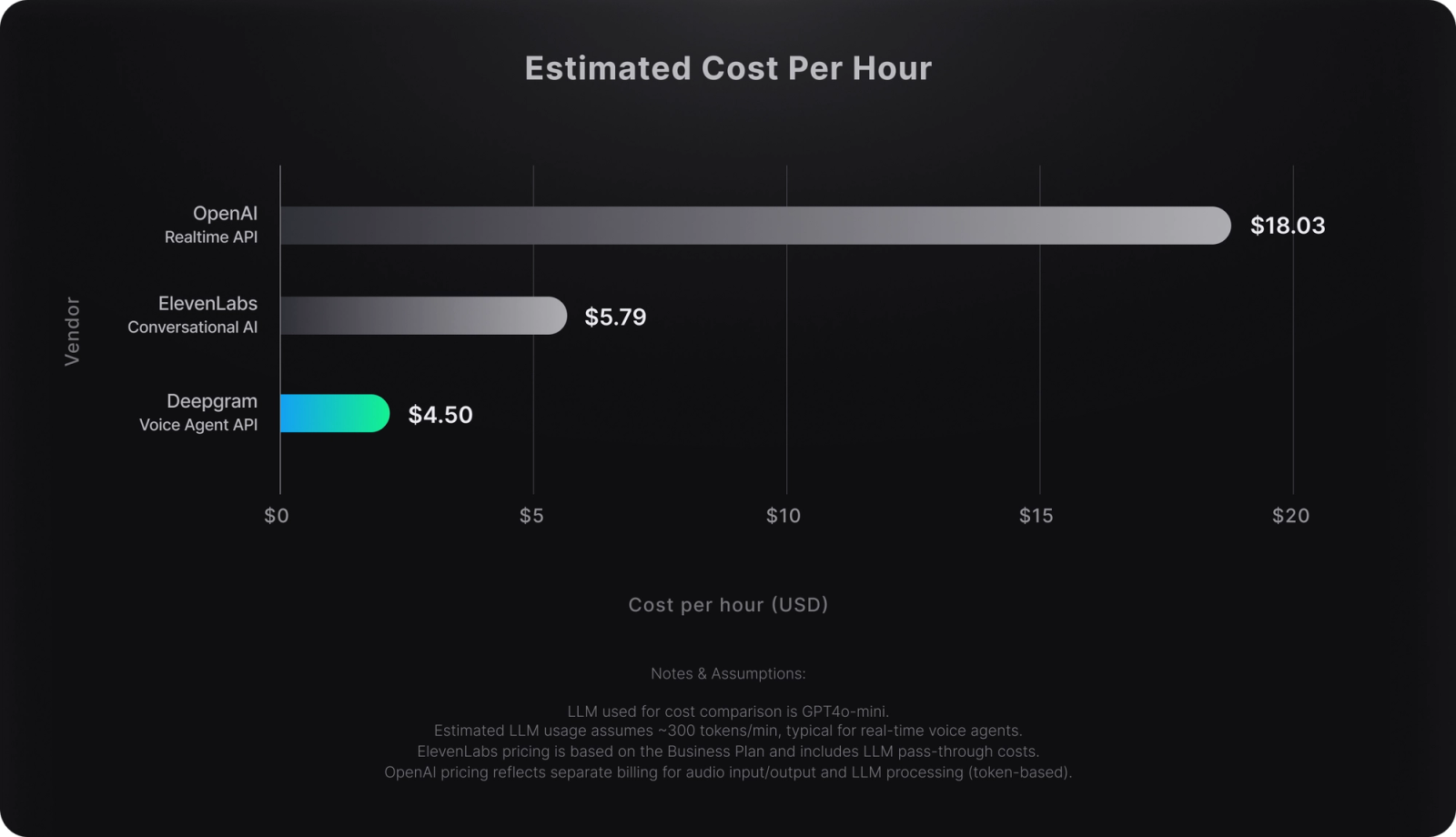
- Priced at $4.50/hour, Deepgram delivers complete voice capabilities at 24% less than ElevenLabs Conversational AI and 75% less than OpenAI’s Realtime API, with built-in discounts when you bring your own models.
- Try it now in our API playground or start building today. Sign up to receive $200 in free credits.
Voice Agent API is Now Generally Available
Voice agents have advanced rapidly, but most systems still struggle to meet real-time production demands. Latency, mistimed responses, and implementation complexity continue to create challenges for teams trying to deliver natural, reliable conversational AI.
Deepgram’s Voice Agent API was built to solve these challenges head-on, and we’re excited to share that it’s now generally available. It unifies speech recognition, LLM orchestration, and text-to-speech into a single streaming API designed for real-time, scalable deployment. Priced at $4.50 per hour, it offers a fully integrated path to building context-aware voice agents with less complexity, more control, and predictable costs.
Since our early access launch, teams from Aircall, Jack in the Box, StreamIt, and OpenPhone have started building voice agents using our API. We’ve also expanded support for multilingual agents with Nova-3 multilingual, keyterm prompting, bring-your-own TTS, new SDKs, and self-hosted deployment options.
This post takes an in-depth look at how the API works, what’s built into the runtime, and how it performs on core benchmarks. For teams shipping real-time voice experiences, it offers a closer look at the architecture behind Deepgram’s developer-first voice stack.
Why a Unified Voice Agent API Matters
Building real-time voice agents has traditionally meant orchestrating together separate components for transcription, language understanding, and speech synthesis. This modular setup introduces architectural friction. Each service adds latency, exposes different APIs, and creates coordination overhead. Under production load, these handoffs often lead to lag, brittle logic, and missed conversational cues.
Teams are usually forced to choose between:
- Custom stacks that offer control but require heavy engineering investment for turn-taking, state management, and streaming orchestration
- Black-box platforms that simplify integration but sacrifice transparency, flexibility, and controllability
Deepgram’s Voice Agent API eliminates these trade-offs. It provides a single streaming interface that handles the entire voice loop from audio input to agent response through a tightly integrated runtime.
Full Model and Runtime Ownership
Deepgram controls all three core components:
- Nova-3, our best-in-class speech-to-text model, delivers accurate results even in noisy conditions, supports real-time multilingual input, and allows self-service customization through keyterm prompting.
- Aura-2 generates expressive, business-ready speech with domain-specific pronunciation, sub-200ms time-to-first-byte.
- Built-in orchestration is the layer that governs real-time conversation flow, including turn-taking, tool use, and knowledge retrieval, so developers don’t have to manage logic across multiple services.
These components run in a shared environment that supports real-time signaling and coordinated inference. Because Deepgram owns and optimizes the models themselves, it can control timing, accuracy, and interruptibility natively within the models, rather than stitching together behaviors across third-party services.
Transcripts from Nova-3 are incrementally assembled during the user’s turn and sent to the LLM as soon as a likely utterance boundary is detected. Once the response is ready, Aura-2 begins synthesis without waiting for punctuation or fixed silence thresholds. This reduces time-to-first byte, keeps responses interruptible mid-stream, and avoids costly stream resets when users change course or interject.
Simplified Developer Experience
Deepgram’s unified interface removes the complexity of assembling and managing voice agent infrastructure. Developers no longer need to integrate separate STT, LLM, and TTS services or manage coordination logic across APIs. Instead, a single bidirectional API handles the full conversational loop, reducing integration overhead and eliminating failure points between components.
To accelerate development, Deepgram provides SDKs in Python and JavaScript, a self-serve API Playground for rapid iteration, and clear documentation. Teams can move from prototype to production faster, with less setup effort and full control over runtime behavior. The result is a faster build cycle and greater confidence in scaling real-time voice agents.
"We believe the future of customer communication is intelligent, seamless, and deeply human—and that’s the vision behind Aircall’s AI Voice Agent. To bring it to life, we needed a partner who could match our ambition, and Deepgram delivered. Their advanced Voice Agent API enabled us to build fast without compromising accuracy or reliability. From managing mid-sentence interruptions to enabling natural, human-like conversations, their service performed with precision. Just as importantly, their collaborative approach helped us iterate quickly and push the boundaries of what voice intelligence can deliver in modern business communications."
Runtime Intelligence: Natural Conversations, Built-In
Real-time conversations hinge on timing. Voice agents must respond at the right moment, allow for interruptions, and adapt to evolving context. Missing those cues, even by a few hundred milliseconds, can make the experience feel robotic or unreliable.
Deepgram’s Voice Agent API embeds runtime intelligence directly into the stack. Unlike systems that rely on post-processing or external logic, all orchestration is handled natively within the runtime.
Built-in Conversational Control
The API supports intelligent, bi-directional streaming with native control over:
- Turn-taking and end-of-thought prediction
The runtime continuously evaluates speech cadence, timing features, and audio context. The agent begins speaking only when the runtime predicts a natural turn boundary, helping avoid awkward lags or premature cutoffs. - Barge-in detection
If a user speaks while the agent is responding, the system handles the interruption during synthesis. Developers do not need to cancel or reinitialize downstream streams. Transcription resumes immediately and partial input is processed in real time. - Streaming function execution
LLMs can trigger structured functions during the session. These functions are executed asynchronously without pausing speech or breaking the stream. - Real-time prompt updates and message delivery
UpdatePromptlets developers push prompt updates or agent messages at any point in the session, without restarting the stream or reinitializing downstream logic. - Voice switching
UpdateSpeakallows for dynamic voice changes mid-conversation. This supports use cases like switching languages or adapting tone based on user behavior.
Event-Driven Design for Developers
Every interaction is surfaced through structured runtime events. For example, UserStartedSpeaking indicates when speech begins. These events allow developers to stay aligned with the system’s internal state without polling or inference logic. All behaviors, including voice changes, prompt updates, and agent messaging, are coordinated over the same WebSocket session. There is no need for additional APIs or custom code.
Integrated orchestration reduces complexity. Developers get granular control over conversation flow while the runtime manages sequencing and coordination. The result is a system that supports natural, adaptive voice agents with significantly less application-side code.
Benchmarking Voice Agent Performance: Latency, Interruptions, and Response Coverage
A real-time voice agent isn’t just measured by how fast it responds. It must respond at the right time, to the full input, without cutting users off or missing what they said. The Voice Agent Quality Index (VAQI) was designed to evaluate exactly that: how well a voice agent performs in natural, multi-turn conversations under production-like conditions.
VAQI evaluates performance across three dimensions that together define conversational quality:
1. End-to-end Latency
How quickly the agent begins responding after the user finishes speaking. In human conversation, delays beyond 1000ms feel unnatural. Sub-second responsiveness helps maintain flow.
2. Interruption Rate
How often the agent starts talking too early, cutting the user off mid-thought. These false positives break conversational rhythm and typically result from poor end-of-turn detection.
3. Response Coverage
How often the agent fails to respond to something the user said. These dropouts usually stem from incomplete transcription, missed voice activity, or weak handling of short utterances.
All metrics were normalized per conversation to ensure fairness across files with varying complexity. Each dimension was scored independently across 121 conversations per provider and then combined using a weighted formula: 40% interruptions, 40% response coverage, and 20% latency. This weighting was chosen to prioritize conversational timing and completeness, which have a greater impact on user experience than raw speed alone.
How Deepgram Performed
Deepgram ranked #1 overall in the VAQI composite index, outperforming all other providers in total conversational quality. Deepgram’s final VAQI score was 71.5, which is 6.4% higher than OpenAI and 29.3% higher than ElevenLabs. OpenAI tended to respond too slowly and occasionally missed user input, while ElevenLabs responded quickly but was more likely to interrupt or miss parts of the conversation.
This performance reflects both architectural choices and model-level intelligence. Deepgram’s Voice Agent API runs STT, orchestration, and TTS in a shared runtime, reducing pipeline delays and avoiding state mismatches. End-of-thought prediction is handled natively in the transcription model, allowing the system to detect natural pause boundaries without relying on silence thresholds or post-processing logic.
How the Benchmark Was Run
All testing was conducted using consistent prompts and a shared evaluation harness that streamed audio in 50ms increments to simulate real-time input. Each provider was tested on the same 121 audio files. All agents ran with default settings and used comparable LLMs (GPT-4o or 4o-realtime) to ensure parity.
To account for variability in conversation complexity, file-specific normalization was applied. This ensured providers were scored on relative performance per file, not just absolute metrics, and prevented “hard” conversations or extreme latency spikes from skewing the results.
"We believe that integrating AI voice agents will be one of the most impactful initiatives for our business operations over the next five years, driving unparalleled efficiency and elevating the quality of our service. Deepgram is a leader in the industry and will be a strategic partner as we embark on this transformative journey."
Enterprise-Grade Deployment Options
Deepgram’s Voice Agent API is built to support flexible, secure, and scalable deployment in enterprise environments. It can run in Deepgram’s managed cloud, within a private VPC, or on-premises using Docker or Kubernetes. The API delivers consistent latency, event behavior, and orchestration logic across all environments. This symmetry ensures that application behavior remains predictable regardless of infrastructure.
For organizations with compliance or data residency requirements, Deepgram supports HIPAA, GDPR, and regional data hosting through localized deployments. For customers requiring infrastructure isolation, Deepgram offers dedicated single-tenant runtime environments that ensure separation of resources and deployment pipelines.
Bring Your Own TTS
The API also supports bring-your-own-model integrations for TTS. Developers can connect external providers like OpenAI (tts-1), ElevenLabs, Cartesia, or AWS Polly by configuring model IDs, voice parameters, endpoint URLs, and auth headers. Synthesized audio is streamed directly into the active session through the same WebSocket, preserving timing, barge-in, and voice switching behavior without needing separate logic paths.
Because orchestration is managed within the runtime, these external TTS systems function seamlessly. Developers retain all real-time coordination features regardless of which voice model is used.
"Deepgram gives us the flexibility to bring our own models, voices, and customize behavior while controlling how we build and orchestrate our voice agents. Their system seamlessly handles the complexity of real-time voice coordination, letting us focus on creating exactly the experience we want."
Pricing Model and Cost Efficiency
Deepgram offers both a predictable all-in-one rate of $4.50/hour with best-in-class components, or the flexibility to bring your own LLM/TTS at reduced rates.
Many platforms force modular complexity from day one: multiple vendors, billing systems, and unpredictable pricing models just to get started. Recently, ElevenLabs announced they'll begin passing through LLM costs starting June 21, 2025, further raising prices and reducing cost transparency.
For teams wanting to move fast, Deepgram's single-rate option removes this operational overhead entirely. This simplicity allows engineering teams to forecast costs clearly and operate reliably in production. For those with specific requirements, modularity remains available as a choice, not a requirement.
Why Pricing Predictability Matters
For production workloads, total cost of ownership isn't just about the base rate but about predictability under scale. OpenAI’s Realtime API, for instance, is priced per token and can fluctuate widely based on conversation length, prompt size, or LLM behavior.
Real-world testing shows that enabling a system prompt can more than 8x the per-minute cost, pushing rates up to $1.63/min ($98/hr) for the gpt-4o model.
Costs can compound significantly in enterprise scenarios that demand longer conversations, complex function calling, and RAG (Retrieval-Augmented Generation) integrations. As context windows expand to accommodate business logic and conversation history, token consumption can spiral unpredictably.
How We Compare
The chart below shows effective hourly rates for common real-time voice agent configurations:
Deepgram is 24% cheaper than ElevenLabs Conversational AI and 75% cheaper than OpenAI's Realtime API. Because pricing isn't token-based, teams can support long-context conversations and RAG workflows without worrying about usage-based spikes. Deepgram's vertically integrated runtime also delivers unmatched compute efficiency, optimizing every stage of the speech pipeline to minimize infrastructure costs while maintaining real-time responsiveness.
“Deepgram’s Voice Agent API stands out for its technical prowess, affordability, and flexibility, making it the smart bet for customer service voice AI.” — Bill French, Senior Solutions Engineer, StreamIt
"Deepgram’s Voice Agent API stands out for its technical prowess, affordability, and flexibility, making it the smart bet for customer service voice AI."
Start Building with Deepgram’s Voice Agent API
With the Voice Agent API now generally available, teams are moving beyond prototypes and deploying voice agents in production environments. The platform’s unified architecture, built-in orchestration, and model-level turn-taking give developers the tools to move quickly while maintaining control, reliability, and scalability.
Companies are already building with Deepgram’s Voice Agent API to support customer service, telephony, and AI-native product experiences. Many cite reduced engineering effort, greater flexibility, and faster time to market as key benefits.
This is just the beginning. Deepgram is continuing to invest in the platform with expanded BYO support, advanced orchestration capabilities, and native telephony integrations planned for the roadmap.
Try it in our API Playground, explore the docs, or claim $200 in free credits to start building today.








