Ditch the grunt work. Start making things happen.
You didn’t get into this to spend your days on the mind-numbing task of transcribing, labeling, and prepping audio files looking for a diamond-in-the-rough insight. With Deepgram, you can ditch the grunt work and create models ON TOP of accurate transcripts. Go ahead, start building new models that knock their data-loving socks off

Maximum Accuracy at All Times
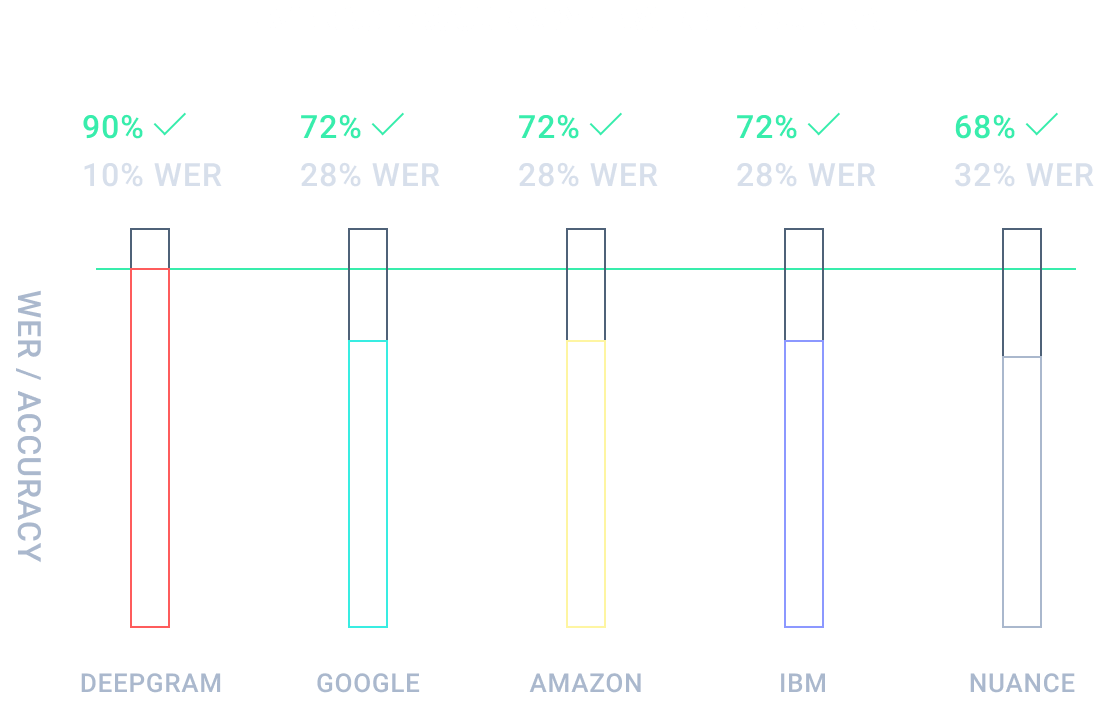
We’ve rebuilt ASR with end-to-end deep learning, powered by NVIDIA GPUs. Our approach allows us to deliver 70% accuracy out of the box, and reach over 95% accuracy with state-of-the-art AI model training. Use models trained specifically for your audio needs and start delivering ground breaking insights.
Create a rock-solid foundation for analytics.
Finally, parsable speech data that you can reliably use for analysis. With our easy to use API, developers or data scientists can add transcription features for usability such as punctuation, diarization, and sentiment analysis.
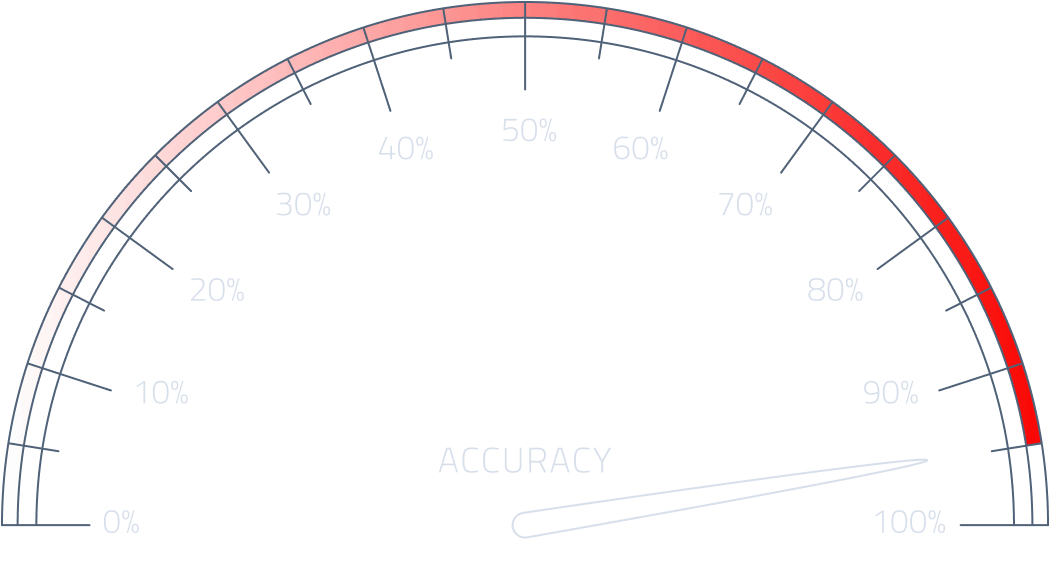
+90%
Accuracy
120x
Faster
11
Deep Learning Patents
100’s
of Models Running Simultaneously
+1 Trillion
Words Processed and Growing