Why Speed is Everything for AI Agents: Benchmarks, Metrics, and Real-World Impact

Humans typically respond in 200 milliseconds in a conversation. Modern AI agents can now match—and even exceed—this natural cadence. When GPT-4 processes your question and generates a response in under 100 milliseconds, it's not just impressive—it's pivotal for human-AI interaction.
From conversational AI that replies faster than human thought to autonomous vehicles making split-second decisions, speed transforms how we interact with technology.
Imagine an AI agent that understands you and responds before you've finished speaking. It’s incredible! Today's language models can process speech in real-time, analyze context on the fly, and generate responses faster than human cognition.
Speed doesn’t just improve functionality—it builds trust. When users see AI agents consistently respond at human-like speeds, their confidence in these systems grows. Here’s a high-level overview of what you can expect from this article:
Why speed is a critical factor in AI agent performance and trustworthiness.
Real-world examples of AI agents excelling with real-time responses.
Actionable insights for deploying high-speed AI systems effectively.
Benchmarks and insights into how speed drives AI adoption, trustworthiness, and competitive advantage.
By the end of this article, you’ll gain actionable insights into using speed to deploy AI agents that are both efficient and indispensable.
⚡️ The Need for Speed In AI Agents
Watch a human conversation, and you'll notice a distinct rhythm. A question, a 200-millisecond pause, an answer.
Now, imagine you’re speaking to an AI agent about a complex technical issue. Instead of waiting for you to finish your entire explanation, the AI processes your speech in real-time, understands the context, and can interject with clarifying questions—just like a human expert would.
This is possible because modern AI systems can:
Process and respond simultaneously: The latest language models don't wait for complete sentences. They process language streams continuously for natural back-and-forth dialogue.
Maintain context at speed: Even while processing at superhuman speeds, these systems have long context windows to keep track of conversation context, memory for previous interactions, and user preferences.
Scale without slowdown: Unlike human operators who slow down under pressure, AI agents maintain consistent response times even during peak loads.
🧠 Understanding AI Agent Speed
AI speed comprises two key components: processing time and response time.
Processing time: The duration for the AI system to analyze data and generate an output.
Response time: The total time to complete an interaction, including processing, data retrieval, and network latency.
Efficient processing allows AI agents to handle complex tasks rapidly so that users stay engaged. Even minor delays can have critical consequences for real-time applications like autonomous vehicles or fraud detection.
For instance, in mission-critical applications like NASA's communication systems, where Deepgram processes massive amounts of audio data, every millisecond matters.
This is also the case in autonomous driving, where delays as brief as 50 milliseconds can compromise safety. The same is true for fraud detection: quick responses are necessary to stop transactions that seem fishy from going through.
🚀 Why Speed Matters More Than Ever
Every millisecond, from the moment a user inputs a query to the delivery of a response, determines whether an AI agent feels seamless or sluggish. Users today expect instant responses from AI systems. Delays cause frustration and disrupt cognitive flow, trust, and engagement.
Here's why speed is a critical factor:
Trust building: Users rely on AI systems to consistently provide rapid, accurate responses. This trust drives adoption in healthcare, finance, and customer support industries.
Competitive edge: Speed can be a deciding factor in competitive markets. Businesses offering faster AI-driven services gain an edge, attracting users who value efficiency.
Cognitive flow: Fast AI responses help users maintain focus. Studies show that delays exceeding 500 milliseconds disrupt cognitive flow, forcing users to context-switch and reducing the interaction's effectiveness.
⏳ The Cost of Slow AI Systems
When AI agents fail to meet speed expectations, the consequences extend beyond user frustration:
Decreased adoption: Users abandon sluggish systems for faster alternatives.
Reduced productivity: Employees waste time waiting for responses.
Lost opportunities: The compromise in real-time decision-making results in missed opportunities.
Only the fastest, most efficient systems will thrive as AI becomes integral to businesses and daily life.

🏆 Real-World Examples of Speed in Agentic AI
Speed is defining how AI agents perform and interact with users. Across industries, faster processing times drive better outcomes, from improving user experiences to enabling life-critical decisions.
Here are four compelling examples that illustrate the transformative power of speed in AI.
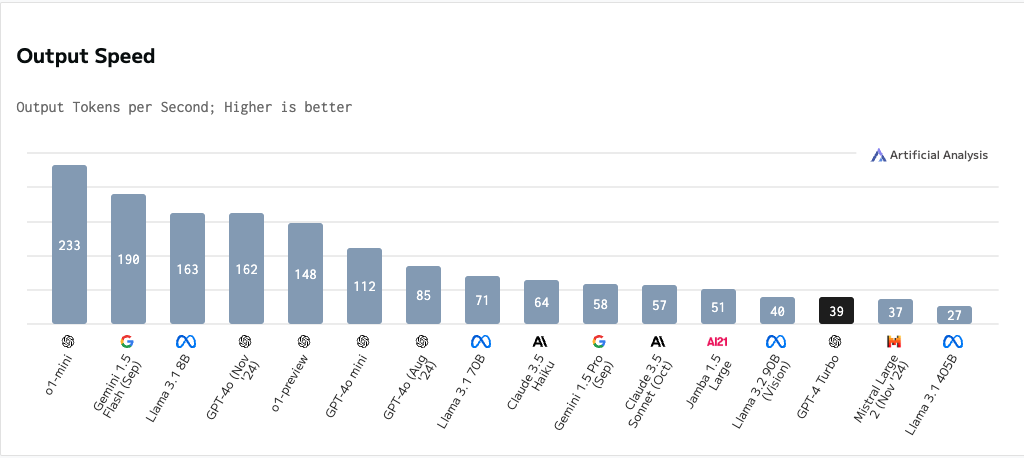
✨ 1. GPT-4o: Real-Time Text and Audio Generation
In conversational AI applications like ChatGPT, response time directly impacts user experience. Response times for earlier versions, like GPT-4, ranged from 6.1 to 41.3 seconds.
GPT-4o has dramatically lowered the latency to just 232 milliseconds for audio inputs and 320 milliseconds overall. This improvement makes interactions feel more natural, so they do not hinder your cognitive flow.
For example, when tested in Voice Mode, GPT-4o outperformed GPT-3.5 and GPT-4 by cutting latency by over 85%. GPT-4o could instantly process complex queries, maintaining conversational rhythm and user engagement. This advancement bridges the gap between human-like conversation speeds and AI responses.
🚗 Autonomous Vehicles: Faster Decisions for Safer Roads
Autonomous vehicles are perhaps the ultimate example of AI speed in action. When a child runs into the street, a human driver takes 250 milliseconds just to recognize the danger. Modern autonomous vehicles can detect the situation, process the sensor data, interpret the road conditions, and initiate braking in under 100 milliseconds.
Tesla's FSD Chip for Autopilot can process data from cameras and sensors at 2,300 frames per second. The dual-chip system, capable of 36 trillion operations per second, ensures redundancy and safety while maintaining real-time responsiveness. This rapid processing enables:
Real-time object detection and lane navigation.
Coordination across safety systems in under 100 milliseconds.
Reduction in collision risks by 20-50% compared to human drivers.
📊 High-Frequency Trading (HFT): Winning in Microseconds
In financial markets, milliseconds define success. Trade speeds below 1 millisecond directly translate to financial gain. Modern trading systems rely on low-latency infrastructure to execute trades faster than competitors, impacting market dynamics:
Trades occur within microseconds to milliseconds, depending on conditions.
Firms with faster systems capture more opportunities and improve market liquidity.
Delays in HFT can disrupt bid-ask spreads, trading volumes, and price stability, as demonstrated during system interruptions.
Speed differences become even more critical during high-volatility events, highlighting the importance of maintaining low-latency systems.
🗣️ Real-Time Speech Processing In Customer Interactions
In customer service, real-time speech processing transforms call center operations:
Speed: Tools like Deepgram’s Nova-2, transcribe one hour of audio in 12 seconds—40x faster than traditional methods.
Accuracy: They analyze sentiment and provide insights with 30% higher accuracy.
Cost efficiency: Businesses report 20–30% cost reductions through optimized GPU infrastructure.
These systems ensure seamless human-machine interaction, improving first-call resolution and enhancing customer satisfaction. For example, agents using real-time transcription can respond instantly to customer queries, creating a natural conversational flow.
🏥 AI-Powered Medical Assistants: Revolutionizing Clinical Workflows
Medical assistants powered by AI-powered transcription tools like DeepScribe and Deepgram’s Nova-2 Medical Model save physicians time by generating clinical notes in real-time with transcription accuracies of up to 99%.
3.3 hours saved per week per physician.
72% reduction in documentation time compared to traditional methods.
They improve efficiency and let doctors focus on patient care by ensuring real-time documentation is done during visits.
🔖 Bookmark: The Benefits of AI Medical Transcription.
🏆 How Speed Transforms AI Agents from Impressive to Indispensable
When an AI agent responds faster than you can complete your sentence, it transforms from a tool into a trusted partner. Picture a customer service scenario: A caller explains a complex technical issue, and before they finish speaking, the AI agent has already:
Transcribed their words in real-time.
Understood the context.
Retrieved relevant solutions.
Started formulating a response.
This process happens in milliseconds, creating a conversation that feels as natural as talking to a human expert. This isn't just about impressive metrics—it's about creating natural and effortless experiences.
💼 Competitive Advantage
Real-world data shows that fast AI systems have measurable effects that improve both the customer experience and operational efficiency:
86% of consumers leave a brand after two poor experiences.
52% of customers expect responses within one hour.
Conversion rates decrease by 7% for every 100 ms of delay.
For websites and digital platforms, the relationship between speed and user engagement is equally clear:
A two-second delay increases bounce rates by 103%.
Pages loading in 0.9 to 1.5 seconds achieve the lowest bounce rates.
Speedy AI services help businesses retain customers and boost loyalty. For example, customers are 2.4 times more likely to stay with brands that resolve issues quickly, demonstrating how speed directly impacts long-term business success.
📈 Efficiency and Productivity Gains
Speed reduces latency, facilitates smooth workflows, and allows real-time decision-making. Companies implementing real-time AI solutions report:
25% shorter production cycles through process optimization.
65% better service levels with real-time analytics.
Revenue growth for 63% of adopters, according to recent studies.
In manufacturing, AI agents reduce logistics costs by 15% and improve production output by 20%, ensuring smooth, efficient operations.
💰 Cost Reduction
By accelerating task completion, AI agents optimize resources and reduce operational expenses. Notable impacts include:
70-80% lower support team workloads with AI-based automation.
85% faster customer response times.
41% cost reductions in supply chain operations.
Companies like Five9, with their Inference Studio 7 product powered by Deepgram, enable real-time transcription and sentiment analysis, saving call centers up to 30% in operating costs while improving resolution rates.
⚙️ Scalability and Flexibility
Modern AI systems scale effortlessly to handle fluctuating workloads while maintaining consistent performance. According to Microsoft Azure benchmarks:
AI workloads grow at a 30% annual rate in public clouds.
Systems achieve 8.6x to 11.6x performance improvements over standard solutions.
This scalability ensures businesses can adapt to demand spikes without compromising response times or service quality.
🔒 Trustworthiness and Reliability
Speed builds trust by meeting user expectations for prompt, reliable interactions. Research shows users expect:
0.1 seconds for instantaneous reactions.
1 second to maintain cognitive flow.
10 seconds before disengagement occurs.
For example, AI agents in regulated industries like finance adhere to strict response time thresholds, such as reporting transactions within one minute. Meeting these FINRA's standards ensures compliance and builds trust in the system’s reliability.
🛠️ Achieving Real-Time Performance in AI Agents
Real-time performance is essential for AI agents to provide instantaneous, accurate responses and handle complex tasks efficiently. This requires combining advanced optimization techniques, hardware innovations, distributed computing architectures, and model compression.
🔍 Optimization Algorithms: Reducing Latency and Enhancing Efficiency
Modern AI systems achieve real-time performance through optimization techniques that reduce computational overhead. These include:
⚡ Low-Level Optimizations:
Vectorized operations: Speed up processing by 3-4x through parallelism.
INT8 quantization: Cuts memory use by 75% with minimal accuracy trade-offs.
GPU-optimized kernels: Deliver 2-10x performance gains.
🧩 Algorithm Innovations:
Flash Attention: Lowers memory usage by 80% in transformer models.
Dynamic batching: Boosts GPU utilization by up to 40%.
These optimizations enable organizations to deploy complex AI models that balance speed, accuracy, and cost efficiency.
💻 Hardware Acceleration: The Backbone of Real-Time AI
Specialized hardware accelerates AI processing, ensuring real-time performance at scale. Key advancements include:
GPUs: NVIDIA H100 GPUs achieve 2x the performance of previous models.
Custom silicon: Meta’s chips reduce energy consumption by 40%.
Cooling systems: Liquid cooling increases server density by 35%.
These innovations enhance processing speed, reduce power consumption, and lower operational costs, making real-time AI more accessible.
🌐 Distributed Computing: Scaling AI for Real-Time Responses
Distributed architectures optimize AI performance by using:
Parallel processing: Reduces latency with load balancing across nodes.
Edge computing: Cuts round-trip latency by 50-200 ms through local processing.
High availability: Achieves 99.9% uptime with redundant systems.
By processing data closer to its source, edge computing improves the user experience and reduces bandwidth usage.
🔗 Managing Data Bottlenecks
Efficient data flow is critical for real-time AI agents. Advanced architectures address bottlenecks by integrating:
Reflex systems: Enable rapid responses to environmental changes.
Continuous feedback loops: Optimize decision-making over time.
Hybrid models: Combine instant reactions with long-term planning.
This ensures AI agents maintain speed and accuracy across diverse workloads.
⚖️ Balancing Model Complexity and Real-Time Performance
Deploying efficient AI agents requires balancing computational demands with accuracy. Techniques include:
Knowledge Distillation: Shrinks models by up to 90% while preserving essential features.
Pruning: Removes redundant parameters, reducing model size by 80%.
Quantization: Improves inference speed while minimizing memory usage.
AI systems achieve real-time performance on resource-constrained devices by reducing model complexity.
🔻 Explore: How to Forget Jenny's Phone Number or: Model Pruning, Distillation, and Quantization, Part 1,
📊 Benchmarks and Metrics for AI Speed
Achieving optimal AI performance requires precise measurement and benchmarking across various metrics. Latency, throughput, and domain-specific metrics like token generation rates help assess AI agent performance across multiple applications.
Benchmarks and metrics ensure AI systems meet both technical and user-experience standards. This section outlines measuring response times, adopting industry standards, and setting realistic speed goals.
⏱️ Measuring Response Times
AI performance is measured by key metrics that reflect system responsiveness:
Latency: The time from a request to the first response.
Time-to-First-Token (TTFT): The delay before an AI model generates its first output token (critical for NLP).
Tokens Per Second (TPS): The rate at which models generate tokens during sustained output.
Throughput: The system’s ability to process multiple simultaneous requests.
🧰 Tools for Measurement
Accurate benchmarking requires specialized tools:
System-Level Tools:
nvidia-smi: GPU performance monitoring.
perf: CPU-level performance analysis.
Model-Specific Profilers:
PyTorch Profiler and TensorFlow Profiling Tools: Analyze bottlenecks in model computation.
Custom Benchmarking:
Load testing frameworks simulate real-world scenarios to reveal system scalability and responsiveness.
🏅 Industry Standards
Benchmarking standards ensure consistent evaluation across AI applications:
MLPerf Inference: Measures inference speed for tasks like image classification and NLP.
Eleuther AI-Language Model Evaluation Harness: Evaluates NLP model speed and accuracy.
Stanford HELM: Provides a comprehensive evaluation of language model capabilities.
Metrics vary by domain:
🎯 Setting Speed Goals
To deliver seamless user experiences, AI systems must meet specific performance benchmarks:
Chat applications: TTFT <100ms, 40+ tokens/second sustained generation.
Voice assistants: End-to-end latency <500ms for natural, real-time responses.
Image generation: Initial previews delivered within 2 seconds.
High-Frequency Trading: Sub-microsecond processing to execute trades efficiently.
🌟 Example Highlight:
Deepgram’s Voice Agent API achieves <250ms end-to-end latency for real-time speech processing with Aura for smooth conversation flow and high-throughput processing to handle large audio workloads.
This way, they can deliver superior user experiences compared to traditional solutions.
📈 Continuous Improvement Through Monitoring
Achieving and maintaining these benchmarks requires:
Real-time dashboards: Continuously monitor latency, throughput, and bottlenecks.
Automated regression detection: Identify performance drops with minimal manual intervention.
Benchmark-driven development: Compare performance against industry leaders on platforms like MLCommons and lmarena.ai (from lmsys.org) using tools like MLPerf.
Organizations that set clear service level objectives (SLOs) and invest in robust monitoring tools can ensure their AI agents maintain competitive performance.
Organizations can deliver AI systems that meet real-time speed expectations by measuring key metrics and aligning performance goals with user needs.
Achieving these benchmarks ensures faster, more responsive AI agents that drive user trust, satisfaction, and business value.
✅ Conclusion: Why Speed is Everything for AI Agents
Speed is more than a metric—it’s the defining factor that moves artificial intelligence from an impressive innovation into a vital tool that shapes how we work, communicate, and solve problems.
Milliseconds can significantly impact success and failure in various industries, and AI agents that prioritize speed consistently demonstrate their worth in practical applications.
From autonomous vehicles making split-second decisions to high-frequency trading algorithms executing perfectly timed transactions and medical assistants delivering real-time support, speed is the common denominator driving AI's practical impact.
This influence extends across critical dimensions:
User experience: AI systems that respond quickly or faster than humans create fluid, intuitive interactions.
Trust and adoption: Reliable, rapid responses build confidence in AI, encouraging widespread adoption.
Competitive advantage: Organizations deploying faster AI agents achieve higher customer satisfaction, operational efficiency, and market share.
Innovation potential: Real-time performance unlocks applications and possibilities that were previously unattainable.
As AI continues to integrate into critical areas of business and daily life, the importance of speed will only grow. Organizations prioritizing speed as a fundamental driver of value and effectiveness will compete and define the new standard for innovation and performance.
❓ Frequently Asked Questions and Answers on Why Speed is Everything for AI Agents
🤔 Why is Speed so important in AI Agents?
Speed is crucial for AI agents, impacting user experience and system effectiveness. Fast inference reduces latency, handles workloads synchronously, and maintains user attention. Subsecond response times are essential for real-time applications like autonomous vehicles or emergency services.
🚀 How can I improve the speed of my AI Agent?
A multi-faceted approach involving hardware and software optimizations is needed to enhance AI agent speed. This includes reengineering software architecture, scaling backend compute power, implementing distributed computing, prioritizing critical functions, optimizing network configurations, and implementing efficient caching strategies.
🔐 How does speed impact user trust in AI systems?
Speed is crucial for building and maintaining user trust in AI systems. Quick responses create an illusion of instantaneous interaction, encouraging creative problem-solving. Slow responses can erode trust and impact system adoption, especially in real-time decision-making applications.




Unlock language AI at scale with an API call.
Get conversational intelligence with transcription and understanding on the world's best speech AI platform.