

Artificial intelligence is trending. From ChatGPT to TikTok anime filters, our interaction with AI is increasingly the norm. For better and worse (we think better), AI is here to stay.
But whether you’re a fancy-pants software developer or a curious mind googling whether or not intelligent robots are going to take over the world, we all face one common problem when hopping into the AI discussion: There’s so much new information out there on the topic that it can be hard to keep up. And it’s even harder to catch up.
We’re here to help.
Below are a series of common terms that researchers, bloggers, podcasters, programmers, and nerds AI professionals like me use all the time. These are terms that we, as flawed human beings, tend to take for granted. Articles and videos often assume a certain amount of baseline knowledge from its audience. Let this dictionary serve as the foundation on which to build that knowledge.
Welcome to the AI community! Here’s how we talk.
The Big Term
Artificial Intelligence
Artificial intelligence is a branch of computer science that revolves around giving computers the ability to perform tasks that previously, exclusively required human intelligence. These tasks include writing essays, creating music, producing art, and playing games.
However, AI can also go beyond what humans have the time or energy for. An artificially intelligent computer can look through thousands of emails in seconds and accurately categorize which ones are spam and which ones aren’t. Meanwhile, in the chess world, even top grandmasters get exhausted after hours of calculating moves. AI computers, however, will not only find better moves, but they will also never get tired as long as they’re plugged in.
Words about using A.I.
Model
Another word for an artificially intelligent computer program. GPT-3 is a model. ChatGPT is a model. DALL-E is a model.
We call these things "models" because they are a statistical representation of the massive amounts of data they’ve been exposed to. For instance, upon exposing DALL-E to massive amounts of art, it gains the ability to calculate, pixel-by-pixel, brand new images—images of what it algorithmically determines to look like human art.
This word is broad and is often used as an umbrella term. Here are a couple common types of models:
Generative models: These are AI programs that create (read: generate) never-before-seen outputs based on user inputs. ChatGPT is a generative model. In fact, the “G” in GPT stands for “Generative.” DALL-E is also a generative model, but instead of generating words, it generates art.
Classification models: These AI programs take in some set of inputs and categorize them. For example, spam-filters are classification models. They categorize (read: classify) every email you get as either “spam” or “not spam”.
Engine
This term typically refers to AI models or AI algorithms within the context of a system. The AI chessbot “Stockfish” is an engine. So is its popular kitten-counterpart, Mittens. IBM’s Jeopardy-playing robot Watson is also an engine. Why? Well, in the same way an automobile engine makes your car run, an AI engine is what makes a decision-making system run.
Let’s put it this way: We refer to an AI as an “engine” when that AI is the brains behind some larger operation.

Watson’s brain is AI, but the part of Watson that presses the button on its clicker is just another computer program. So is its speaking functionality. Likewise, Mittens has an AI brain that calculates lengthy chess move sequences, but its trash-talking is just another print function—a function similar to the one that first-time coders use to say “Hello World!”
For further reading: Here’s a list of some of the more well-known AI engines you may have heard of.
“Learning” terms
Machine Learning (ML)
This term refers to the process by which computers become artificially intelligent. After all, in order to become intelligent, you must learn.
At its heart, machine learning is an extreme version of pattern recognition, which is something humans do too. If we give a human millions of news articles to read, that human might find certain patterns after a while. Maybe they find out which writers have an affinity for certain phrases. Maybe they find that other writers tend to collaborate on more complex topics. Maybe they find that a particular word rose in popularity in the year 2009, which may indicate a trend at the time.
Well, a computer would be able to find all those patterns and more in much, much less time. A human may take decades to read millions of articles. Meanwhile, it took less than a year for us to get from GPT-2 to GPT-3. And these machines read billions of words. Not to mention, they can find patterns that we wouldn’t even know to look for. That’s why your YouTube homepage knows what new videos you’re going to enjoy before you do. Same for your Instagram suggestions and your TikTok “For You Page." And remember, millions of videos and images are posted every day on these sites.
When computers find patterns among massive amounts of data, we call this “machine learning." And, as we’ll see later, finding patterns can lead this AI to do incredible things, from outplaying humans at their own games to understanding almost any language.
Deep Learning
This term, just like its cousin “neural networks” (defined below), is quickly reaching buzzword status. Luckily, it’s not too scary once you look it in the eye.
Deep learning is simply a type of machine learning. In the same way a chicken is a specific type of bird, deep learning is a specific type of machine learning. Specifically, deep learning uses neural networks. We’ll discuss neural networks more in depth later. But all you need to know about deep learning is that it is a specific method of machine learning.
Of course, for bonus points, you can read up on IBM’s detailed description of deep learning.
“Data” terms
Before delving into the data terms, it’s important to understand why data and AI go hand-in-hand.
Long story short, before a computer program like DALL-E can create art, it first has to see a lot of art. Before ChatGPT can write essays or episodes of Seinfeld, it first has to read a lot of similar material. Before Stockfish can beat you at chess, it first has to watch and play a lot of chess.
This exposure to various types of material—art, writing, chess games—is called "training." And the material itself is the data. Here’s the vocabulary for such data:
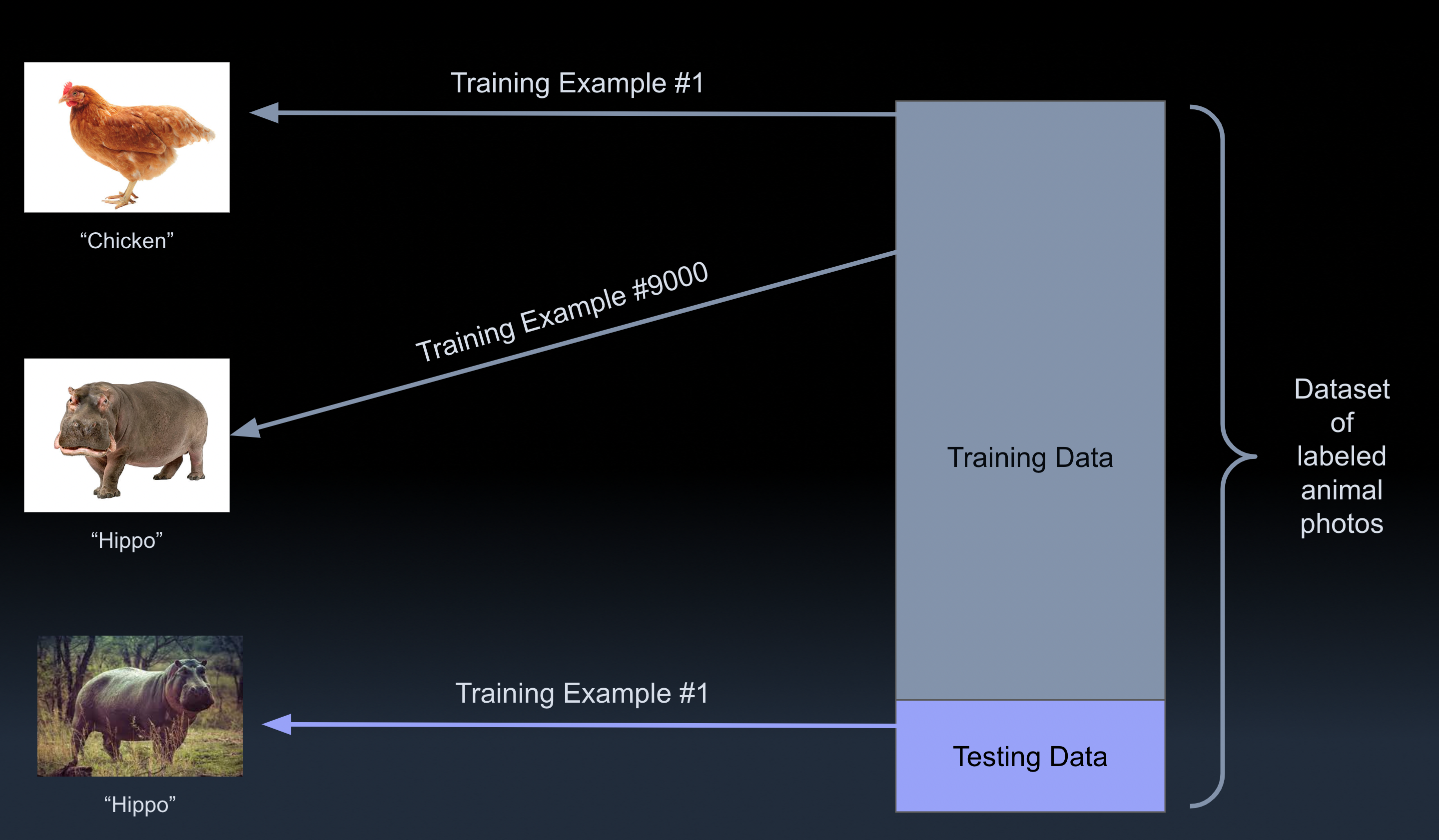
Training Data
This is what folks call “grist for the mill” when it comes to AI. For example, if you’re training an AI to recognize pictures of different animals, your training data could contain thousands of pictures of bees, each labeled with the word "bee." The training data would also contain labeled pictures of sharks, dogs, gorillas and whatever else you’d like it to identify.
Testing Data
After a model is trained, developers use another set of data to see how much their AI learned. They do this by examining how well it performs on data it hasn’t seen yet. That is, testing data consists of information that was not present in the training data. Say, new pictures of bees and sharks and gorillas. After all, if the AI model saw a thousand pictures of bees, it should be able to look at a new animal picture and tell if it’s a bee or not. Testing data is formatted in the same way as the training data.
Dataset
A dataset is the collection of testing data and training data together.
AI developers typically receive an entire dataset of, say, labeled images all at once. Most of that data will be used to train a model. Then, around 10–15 percent of the data is manually sectioned off to be testing data, while the rest is training data.
Subtopics of AI
Natural Language Processing (NLP)
The branch of AI dedicated to getting computers to understand language (and all of the complexities, rule-exceptions, and patterns these languages entail). This is the intersection of artificial intelligence and linguistics.
NLP is the reason why your Siri and Alexa can understand you when you talk, why Google Translate is becoming increasingly useful, why search engines understand your questions, why AI can now write code for you, and much more.
Computer Vision
The branch of AI dedicated to getting computers to understand what they see.
Computer Vision is why your Snapchat and TikTok filters can always find your face. And also why iPhone face ID works. And why self-driving cars won’t confuse pedestrians wearing red clothes for stop signs. Computer vision, by the way, relies heavily on neural networks, a term we define below. (For bonus points, know that image recognition primarily relies on a special type of neural network called a “convolutional neural network”. But don’t worry about the details of that just yet. Terms like “Convolutional Neural Network” and “Recurrent neural network” will be in the Intermediate Dictionary.)
Game-Playing
It’s the branch of AI dedicated to solving games. Since computers have the capacity to watch, analyze, and play multiple lifetimes worth of games, they can defeat humans easily. Twenty-five years ago, IBM’s Deep Blue defeated Garry Kasparov, the best chess player of the time and arguably the greatest chess player ever. Likewise, AlphaGo defeated professional Go player Lee Sedol. Just remember, whenever you beat a computer at chess, just know that it was going easy on you.
Note: Checkers has been solved. As of 2007, AI-driven calculations revealed that if both players play perfectly, the game will end in a draw. The only way for one player to win is for the other to make a bad (read: slightly inaccurate) move.
The Nitty-Gritty of Building AI
Below the surface level information about what AI is, we now get to the good stuff: How AI works.
Neural Network (NN)
As mentioned earlier, this term is quickly reaching buzzword status. Nevertheless, it is actually crucial to the world of AI. Although neural networks are not a part of every AI model, they are beautiful and teachable enough to catch the attention of the masses.
A neural network is the system of numbers and calculations that sits “under the hood” of a bunch of AI models. As the name suggests, its structure is inspired by the human brain. Each “neuron” in the network is really just a little box that holds a number. All of these neurons are connected to each other in an elegant, yet complex (sometimes borderline messy) way.
Neural networks are structured in a layered fashion. And, conceptually, each layer understands a little more about the input than the last. As such, the first layer of neurons is the “input layer”. Each neuron in this layer can contain a value manually defined by the person who’s using the NN.
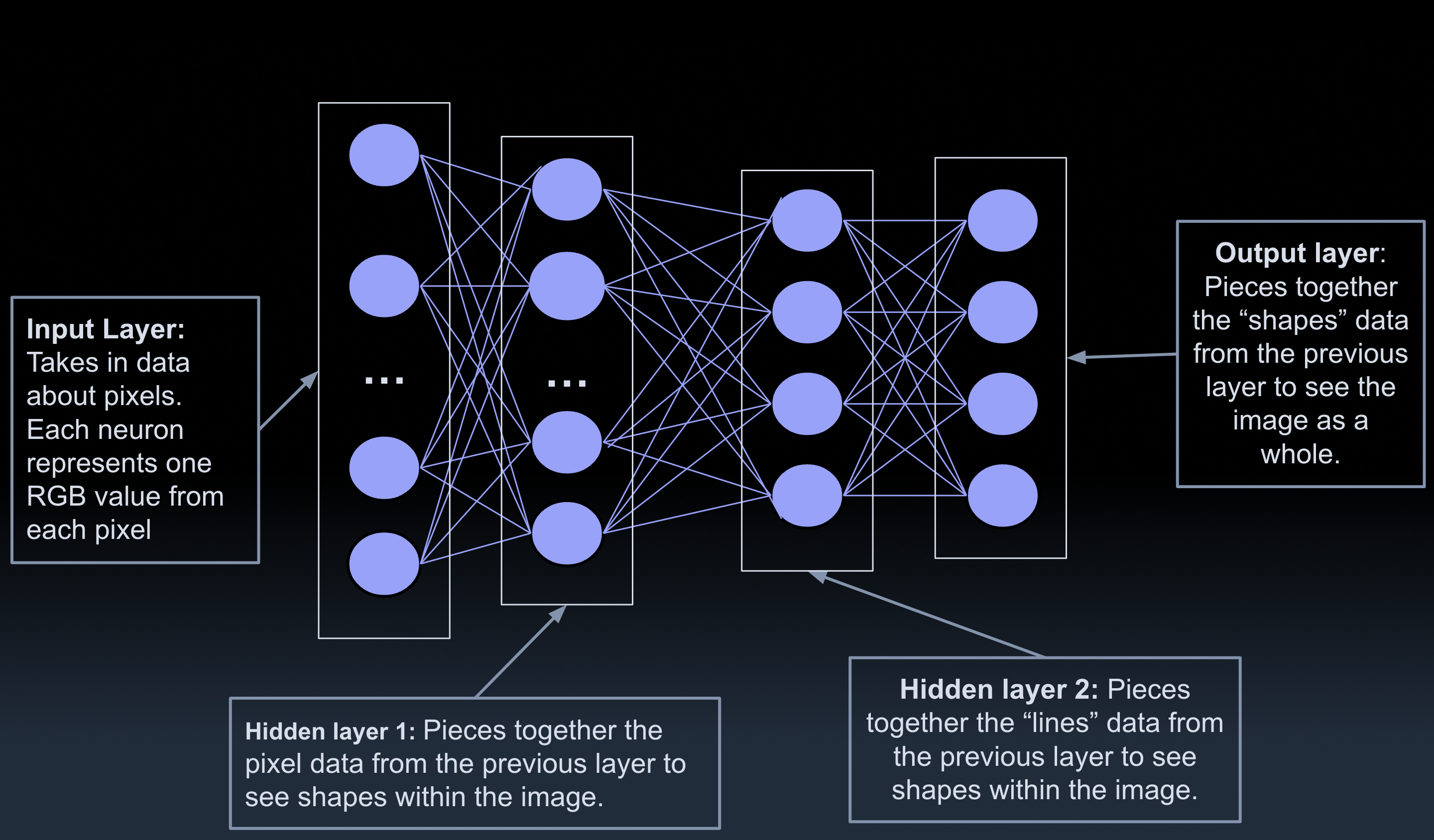
The final layer of neurons is the “output layer”. Again, the output layer consists of a bunch of numbers, specifically probabilities. Such machine-readable probability calculations can be converted into human-interpretable facts and figures. Figures like “The probability that this image contains a dog is 94%” or “Moving the rook to that square is a bad idea because your opponent can win two pawns now.”
Between the input layer and the output layer, there are “hidden layers”. In practice, even the engineers who designed the neural network typically don’t know (and don’t really care) exactly what calculations are going on in there. Although developers know how their neural networks find patterns, they don’t know what the exact values of each hidden neuron are, or how strongly any given pair of neurons is connected. Often, ML users focus mainly on the accuracy and precision of the network’s results.
Note: Not all pairs of neurons are directly connected. Any given neuron only has direct connections to the neurons in the layer right before it and the layer right after it.
If you want a deep dive into the math behind NNs, check out this playlist from the great YouTube channel, 3Blue1Brown.
Weights
In AI-oriented linear algebra, weights are the coefficients within a sum. For example, in the expression 3x+14y, the coefficients would be 3 and 14.
In plain English: Weights are how strongly two neurons are connected to each other. A high, positive weight (e.g. 9001) represents a strong connection. Meanwhile, a weight that is closer to zero (e.g. 0.01) represents a weak connection. Finally, a weight that’s deeply negative (e.g. -1000) represents a repellant connection. Or, in mathematical terms, a inversely correlated connection.
A classic example of weights in AI (and linear algebra in general) is in predicting the price of houses. A few factors go into determining the price of a house—number of bedrooms, number of bathrooms, square footage, and so on.
Imagine a house with six bedrooms, six bathrooms, and ten thousand square feet. That house is going to be hella expensive. Now cut the square footage in half. There’s now six bedrooms, six bathrooms, and five thousand square feet. This imaginary house is much cheaper than the original.
Now, instead of removing square footage, imagine we cut the number of bathrooms in half. We’ll end up in a house with six bedrooms, three bathrooms, but still ten-thousand square feet. And while this house is likely going to be cheaper than the original, it’s still going to be more expensive than the five-thousand square foot version.
What do we learn from this example? We find that square footage is probably more important than the number of bathrooms when determining the price of a house. This might not be true in all cases. However, if enough houses follow this trend, then the pattern is there, and the AI will find it.

And if square footage is generally more important than the number of bathrooms in this house-price prediction scheme, then the neuron containing the value of a house’s square footage will have a higher weight than the neuron containing the bathroom count.
Pretraining
This is the process by which a neural network becomes good at its intended task. An untrained neural network has no prior knowledge. It bases its inference on essentially nothing. And when you ask it questions, the best it can do is make guesses based on what little information it’s been exposed to.
For a neural network to improve its performance, it must “know” which pairs of neurons must have strong connections, which pairs of neurons must have weak connections, and which pairs of neurons repel each other.
In other words, for an NN to be effective, it must first figure out which neurons should be strongly connected and which ones shouldn’t.
Fine-tuning
This is the process by which a fully pre-trained neural network gains expertise over a specific domain. Let’s look at GPT-3 to see what we mean.
GPT-3, as mentioned above, is a generative model. So if we give it a prompt, it can create some never-before-seen text. But let’s say that we want to use GPT-3 as more of a conversational buddy rather than a mere prompt-and-response computer.
Well, one thing we can do is take the GPT-3 model—a model that has already been pre-trained to understand and speak English—and expose it to a bunch of conversations. Pure one-to-one dialogue.
The idea is that if we show GPT-3 enough conversations, it will learn how to converse. Or, to put it in terms we’ve discussed above, we can use a dataset of conversational speech to train GPT-3 how to engage in more human conversation.
In our example, GPT-3 is pre-trained to speak English, but then fine-tuned for conversation.
Surprise! That’s the recipe for ChatGPT.
Fine-tuning is the process of exposing an existing model to additional data to give it expertise over a specific domain. In the case of ChatGPT, that domain is conversation. In the case of InstructGPT, that domain is following commands.
Vector
This is a fancy word for a simple concept. A vector is simply a list of numbers. The list can be two numbers long, or it can be a billion numbers long. You may have seen vectors in your school’s physics classes. Those vectors are typically three numbers long—one number for depth, one for width, and one for height.
In AI, a vector is what we use to represent images, audio, videos, or words. After all, computers can’t physically see images in the same way our eyes can. So we turn those images into numbers that computers can understand. And the list of numbers that represents, say, an image is what AI devs are talking about when they say "vector."
Note that these vectors tend to be very long. For example, to represent an image as a vector, here’s what we’d do:
Let’s say that we have an image that consists of a million pixels. Well, each pixel can be represented as a vector of three values: One value for red, one for green, and one for blue, in that order. These values determine the color of a pixel. For example, a purple pixel can be represented by the vector [1 , 0, 1], which indicates that the pixel contains some red, no green, and some blue.
A perfectly green pixel can be represented by [0, 1, 0]. A pitch-black pixel would be [0, 0, 0], and a pure white pixel would look like [1, 1, 1], because if you add red, green, and blue light, you get white.

Now, to represent the entire million-pixel image as a vector, we simply read the pixel values from left-to-right, starting at the top. After concatenating all these pixel-vectors together into one big vector, voila. We have a single vector—three million numbers long—to represent the image.
Vectorization
Also known as “embedding,” vectorization is the process of turning human-readable data into machine-readable data.
Remember, even the most powerful AI models, at their core, are still just computers. And computers know nothing but numbers. Like any program, AI models and engines are a bunch of ones and zeroes. If I type the word “chair” into a computer, that computer won’t know what a “chair” is. All it sees are the characters ‘c’ and ‘h’ and ‘a’ and ‘i’ and ‘r’. And even those letters are just a bunch of binary gibberish to the computer.
To complicate things further, the word “chair” is, quite frankly, pretty complex. There are swivel chairs, and benches, and rocking chairs, and thrones, and armchairs, and recliners… and so on. And we haven’t even mentioned the fact that there are “chairpersons” of company boards, academic departments, and all manner of other committees. And that it’s not uncommon to refer to the chairperson simply as “chair” (ex: “Board chair” as opposed to “chairperson of the board.”)
So how do we get a machine that only knows numbers to comprehend all the things a “chair” can be? Simple: We use vectors.
Now, vectors in AI are not like vectors in physics or linear algebra 101. Vectors, in AI, are extremely long, complex, and typically only contain real numbers (that is, any number that’s not infinity or the infamous imaginary 𝑖). And every single one of these numbers is precisely calculated. But the punchline is this:
AI engineers use vectors to explain data captured from words, videos, pictures, audios, and any other useful data you can think of. And the math-heavy process of turning this human-consumable material into a vector is called "vectorization."
And once the word “chair” or “pawn” or “Jeopardy” has some well-calculated, intricate vector to represent it, the computer now has a way of understanding what all those concepts are.
Parting Words
Phew. We did it! Hopefully the vocabulary of AI makes a bit more sense now. But also know that this list of terms is not comprehensive. The world of AI remains vast, and consequently so remains its language. Nevertheless, consider yourself armed and ready to go spelunking into this world. A world filled with self-driving cars, anime, and some of the greatest technical minds of our generation.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
Note: If you like this content and would like to learn more, click here! If you want to see a completely comprehensive AI Glossary, click here.




Unlock language AI at scale with an API call.
Get conversational intelligence with transcription and understanding on the world's best speech AI platform.