Using AI to Help Me Get into Medical School


Okay, let’s get this out of the way: I am not an actual medical student.
I was kinda serious about becoming a doctor in my undergrad years, but like many who begin the medical route, I was tempted off the path by the world of tech. Now, instead of having an MD, I have a github account.
However, I still think it’d be fun to take the MCAT. Or, at least, it’s fun to take a big test when there are no stakes whatsoever. My score doesn’t matter, so let’s see what shenanigans we can get up to.
Alright, let's go!
Can AI help with test-taking?
My goal here is not to see if Large Language Models can pass the MCAT. We already know that they can. And besides, it’s not as if future medical students are going to let ChatGPT take the test for them.
Rather, my goal is to see if AI can assist in the studying process.
After all, many people on Twitter are throwing around the argument that “An AI won’t replace you, but a person who knows how to use AI will.”
Well, to that assertion I say, “Let’s see.”
Now, before we begin, I do need to mention that the MCAT takes 7-8 hours to complete. Unfortunately, I don’t have that time. So I’m going to take only one section of the MCAT—the Chemical and Physical Foundations of Biological Systems section.
This section tests your Chemistry and Organic Chemistry skills with a touch of college physics in there for good measure. It consists of 59 multiple choice questions, each with four answer choices.
I’m going to take the MCAT Chemistry Section in three different ways:
Random guessing.
Educated guessing with my raw brain.
Educated guessing with my raw brain and an AI-created study-guide.
My hypothesis is that the random-guessing score will be the lowest (around 25%). Then, my “raw brain” score will be slightly higher, but not by much. After all, I’ve only really studied the pre-med path for two out of the typical four years.
Finally, I hypothesize that AI-assisted educated guessing will yield the best results.
How I used AI to study
At this point, it’s common knowledge that AI chatbots like ChatGPT, Houston, and Bard all make errors. As a result, I don’t want to use a chatbot to study, since I don’t want to do the work of fact-checking every single output they produce.
So I’m going to need an AI that will condense information that I already know to be correct.
As a result, I’m using Khan Academy to create a study guide. I trust them, since I’ve been using their videos since high school. And they already have a playlist of videos for this specific section of the MCAT readily available.
And now that I have my source material, the next step is to write some code that will extract the information from these videos and format them into bite-sized chunks for my study guide.
Coding an AI study-guide generator
We’ll be exclusively using Python today. This section of the blog is dedicated to breaking down how I built my study-guide generator. But if you just want to read the code for yourself, check out this github repository.
Here’s the pipeline I landed on:
Take my input playlist of videos and transcribe them into text.
Take the transcriptions and summarize them
Concatenate all the summaries into one gigantic study guide.
This pipeline is illustrated in the image below, where the figure in the top-left represents Deepgram’s latest transcription model, Nova, working to turn the audios into JSON outputs.
Note that if I were taking this test in real life, I would legitimately memorize the study guide verbatim and then take multiple practice tests. That’s how I studied for every major exam I’ve ever had in school.
However, I don’t have the bandwidth right now to memorize 200+ videos’ worth of chemistry material, so I’ll just take the test open-book. After all, being able to reference the study guide simulates the experience of having all the information downloaded into my brain.
And now for the code!
The fastest and most accurate way to transcribe a playlist of videos and transcribe them into text is to use the youtube_dl package to download the audio of the videos as .mp3 files, then to pass those audios into Deepgram’s speech-to-text API.
We’ve already gone over the code to download videos in this blog here. But for convenience’s sake, here’s the code once more:
The only thing you need to change in the code above is the vids variable, which should be a list containing the URLs of the youtube videos you wish to download.
And to transcribe audios using Deepgram, there are a few resources you can use! We have SDKs and Python notebooks. But again, for convenience’s sake, here’s the transcription code we used verbatim:
And finally, we take the transcriptions and pass them into a summarization AI! Here’s what that code looks like:
You don’t really need to modify anything in the code unless you want to reorganize where the various output files are located. In fact, everything you need to know is outlined in the README file of this github repository.
The results…
And so how did we do? Well first off, take a look at the answer choices from each of the three test-taking runs we did.

Overall, each of the three scores were below the median MCAT score of 125 / 132. Or, more explicitly, none of my test-taking trials would actually get me into any medical school. But let’s put some numbers to that conclusion:
Method Raw Score MCAT Score
Random guessing 21 / 59 121 / 132
Educated guessing 20 / 59 121 / 132
AI-assisted guessing 25 / 59 ⭐ 123 / 132 ⭐
As you can see, my “educated” guessing trial run yielded a lower score than my random guessing trial run. As a result, we can conclude that I’d do just as well on the test if I merely clicked random bubbles as I would if I actually took the test while trying to remember my sophomore year O-Chem class.
Or, in other words, I don’t know my chemistry.
Nevertheless, the AI-assisted guessing indeed helped me! Let’s delve into the specifics:
The difference that AI made for me
When I underwent my AI-assisted trial run, I simply took all the answers from my educated-guessing trial run and changed any responses I felt iffy on. It was a simple if-else statement:
As a result, I ended up changing 7 of my original answers. And the best part? I never changed any of the answers that were already correct! My AI-generated study guide never steered me wrong. Rather, it steered me right 5 out of 7 times:
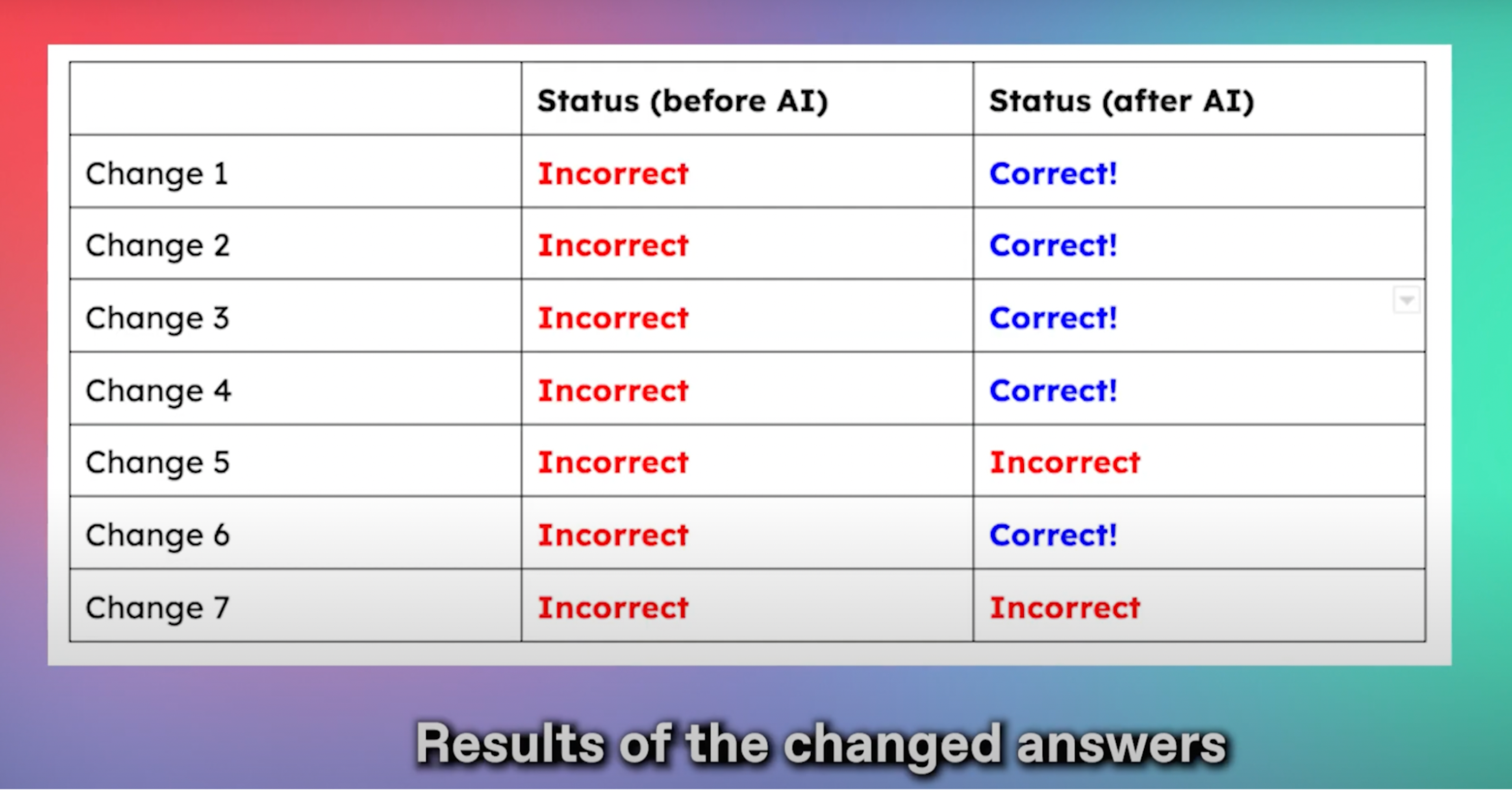
Now, while a 123 / 132 on the MCAT isn’t good enough to get me into medical school, we can conclude that the AI study guide indeed helped me boost my score.
Now will this be the case for everyone? Probably not. But hey, if you have 30 minutes to spare, you can clone the github repo, get API Keys from Deepgram and OpenAI, and create a study guide within minutes! Doing so does no damage, and it may even help. So if you have the technical knowledge, go for it
Conclusion
While AI isn’t going to replace future medical students, we can decently assume for now that a medical student who knows how to leverage AI is at an advantage. And since AI technology is only getting better and better, those technically savvy students will only see their advantage grow as time goes on.
And if you want to see me actually take the MCAT, check out this video:
Now, if you’ll excuse me, I think it’s time for me to become a doctor. If you need brain surgery, a check-up, or if you just want to talk about the code, leave a comment below or reach out to us on our socials! Links below:
Follow us on Twitter: https://twitter.com/DeepgramAI
Follow us on LinkedIn: https://www.linkedin.com/company/deepgram
Follow us on TikTok: www.tiktok.com/@deepgram_ai
Check out our Github: https://github.com/deepgram




Unlock language AI at scale with an API call.
Get conversational intelligence with transcription and understanding on the world's best speech AI platform.