LLM Agents: When Large Language Models Do Stuff For You


You can do a lot with chatbots—especially after several volleys back and forth of refining your prompts, sometimes spelling things out in ridiculous detail just to nudge your chatbot of choice toward your goal (usually some information you’re after).
But this question-reply cycle can grow tedious, and not everyone has the desire or the time to learn meticulous prompt engineering techniques, which is why some folks are trying to get large language models (LLMs) to handle most of this grunt work for them via (somewhat) set-it-and-forget-it autonomous “agents” that not only return the information we want but can also actually do things too.
Several increasingly active, experimental LLM agent-based projects have sprouted up recently, gaining significant momentum. So much so that Andrej Karpathy—former director of Artificial Intelligence (AI) at Tesla and now back with OpenAI, where he started—kicked off a recent LLM agent-focused hackathon at the AGI House with an intriguing forecast of agents’ potential, reckoning that Artificial General Intelligence (AGI) will likely involve some flavor of agent framework, possibly even “organizations or civilizations of digital entities.”
Bold, perhaps, but Karpathy’s vision of LLM agents’ promise isn’t precisely an outlier; sharing similar sentiments, Silicon Valley and venture capital firms are throwing gobs of resources at LLM agents.
To get a glimpse of what Karpathy and others are so excited about, we’ll explore several LLM agent projects, but let’s first hash out what exactly an LLM agent is (if you already know, jump ahead).
What’s with all this “Agent” Talk?
When you think of an agent, you might envision a video game character, a robot, a human, an insect, or something else that exhibits agency (i.e., a capacity to act). LLM agents, however, are closer to written versions of digital assistants like Alexa or Siri.
Before a flashback to Alexa or Siri’s lackluster “assistance” causes you to click away, hang with me. What has some folks so pumped about LLM agents’ potential is that they can tackle more multi-pronged, longer-term objectives than digital assistants currently handle (as you’ll learn in a bit, they can, for example, write mediocre programs and research reports, learn to play Minecraft, or—Hydra-like—spawn more LLM agents).
Since it’s a relatively new concept, folks are using many different terms for LLM agents, including “generative agents,” “task-driven agents,” “autonomous agents,” “intelligent agents,” “AutoGPTs,” and more. And some think all this “agent” talk is way off. Cognitive scientist Alison Gopnik, for example, argues that, rather than so-called “intelligent agents,” LLMs amount to cultural technology, a category into which she also stuffs writing, libraries, and search engines.
And if the term variability isn’t confusing enough, current definitions are also in flux but it’s tough to do better than OpenAI AI safety researcher Lilian Weng's definition of LLM agents as:
While there’s not yet a strong consensus on terms or definitions, for this article, at least, let’s sidestep this minefield of nuance and, borrowing from Weng, roughly define an LLM agent as an LLM-based entity that can manipulate its environment in some way (e.g., a computer, web browser, other agents, etc.) via tools (e.g., terminal, REPL, API calls, etc.) toward some goal (e.g., book a flight, write a business plan, research some topic, etc.) with significant autonomy over a long time horizon (i.e., with minimal human input, an agent decomposes a broad goal into small sub-tasks and decides when that goal is satisfied).
LLM Agents’ Key Components
We now have an idea of what LLM agents are, but how exactly do we go from LLM to an LLM agent? To do this, LLMs need two key tweaks.
First, LLM agents need a form of memory that extends their limited context window to “reflect” on past actions to guide future efforts. This often includes vector databases or employing multiple LLMs (e.g., one LLM as a decision-maker, another LLM as a memory bank).
Next, the LLM needs to be able to do more than yammer on all day.
When a crow carves a twig into a hook to snag tough-to-get bugs from curved crannies, we consider that crow an intelligent agent because it’s manipulating its environment to achieve a goal. Similarly, an LLM must create and employ tools to manipulate its environment to become an intelligent agent.
The common LLM-agent version of a crow’s carved twig is API calls. By calling existing programs, LLMs can retrieve additional information, execute actions, or—realizing no current options suffice—generate their own tool (e.g., code up a new function, test it, and run it).
Beyond allowing LLMs to manipulate their environment, tools also help overcome two inherent LLM weaknesses. They help LLMs utilize more updated information than the information they were trained on (e.g., ChatGPT’s now extinct Bing plugin), and tools allow LLMs to delegate tasks that they lack skills at handling to more capable programs (e.g., ChatGPT’s Wolfram plugin for math).
With our working definition of LLM agents and an overview of their essential components, let’s check out some recent LLM agent projects.
Academic LLM Agent Projects
Though some of the independent LLM agent projects we’ll discuss later arrived on the scene basking in the hype, university groups are also cranking out interesting research on agents. Let’s check out a few of these first because some of what they explored reoccurs in independent projects.
From Language, “The Sims” Emerges
What happens when you craft a few dozen agents, toss them into a virtual, interactive environment reminiscent of "The Sims," and let them interact with one another via natural language?
Park et al. tested this. With each LLM agent (which they dubbed “generative agents”) modeled with an observe, plan, reflect loop, what emerged was surprisingly “believable proxies of human behavior,” including information diffusion (e.g., knowledge of who was running for mayor), relationship formation (i.e., remembering inter-agent conversations), and coordination (e.g., planning a party).
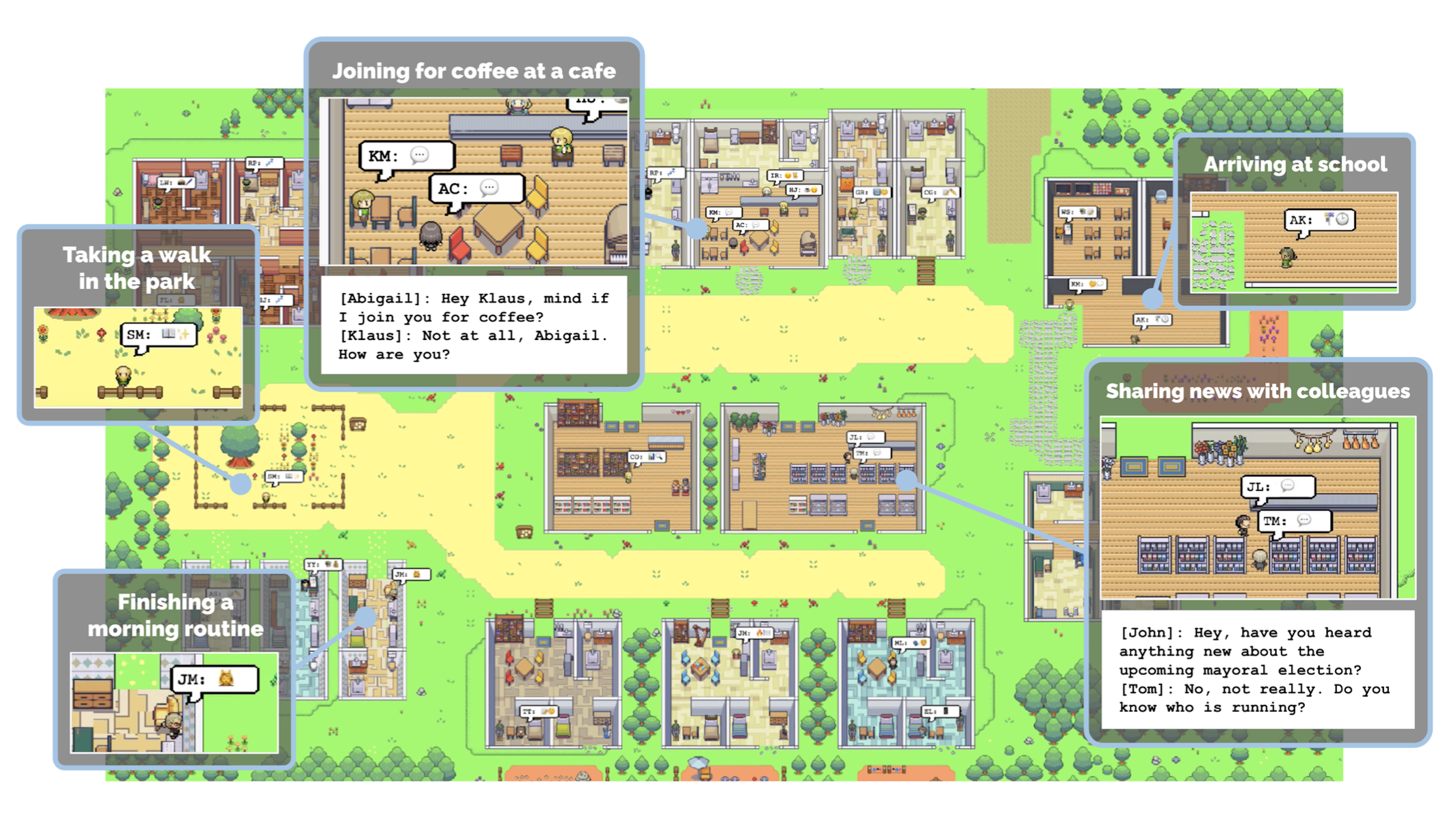
How’d they do this? Since reflection requires remembering, Park et al. augmented their LLM agents with a long-term “memory stream” that, with time stamps, tracked agents’ observations of their own experiences and perceptions of other agents, encapsulated entirely in natural language. The agents stored no additional information about their world.
While memory is a critical component in all LLM agents (because it’s strongly coupled with reflecting, which is tied to planning, which is connected to actions), storing agents’ conversations also served a separate, more pragmatic purpose for Park et al.
When interviewing their agents to check for emergent outcomes (e.g., verifying information diffusion by asking them if they knew who the mayoral candidates were), Park et al. could confirm whether agents were hallucinating by reviewing past conversations and time stamps.
Ok, so these agents remembered stuff. But how did that guide their behavior?
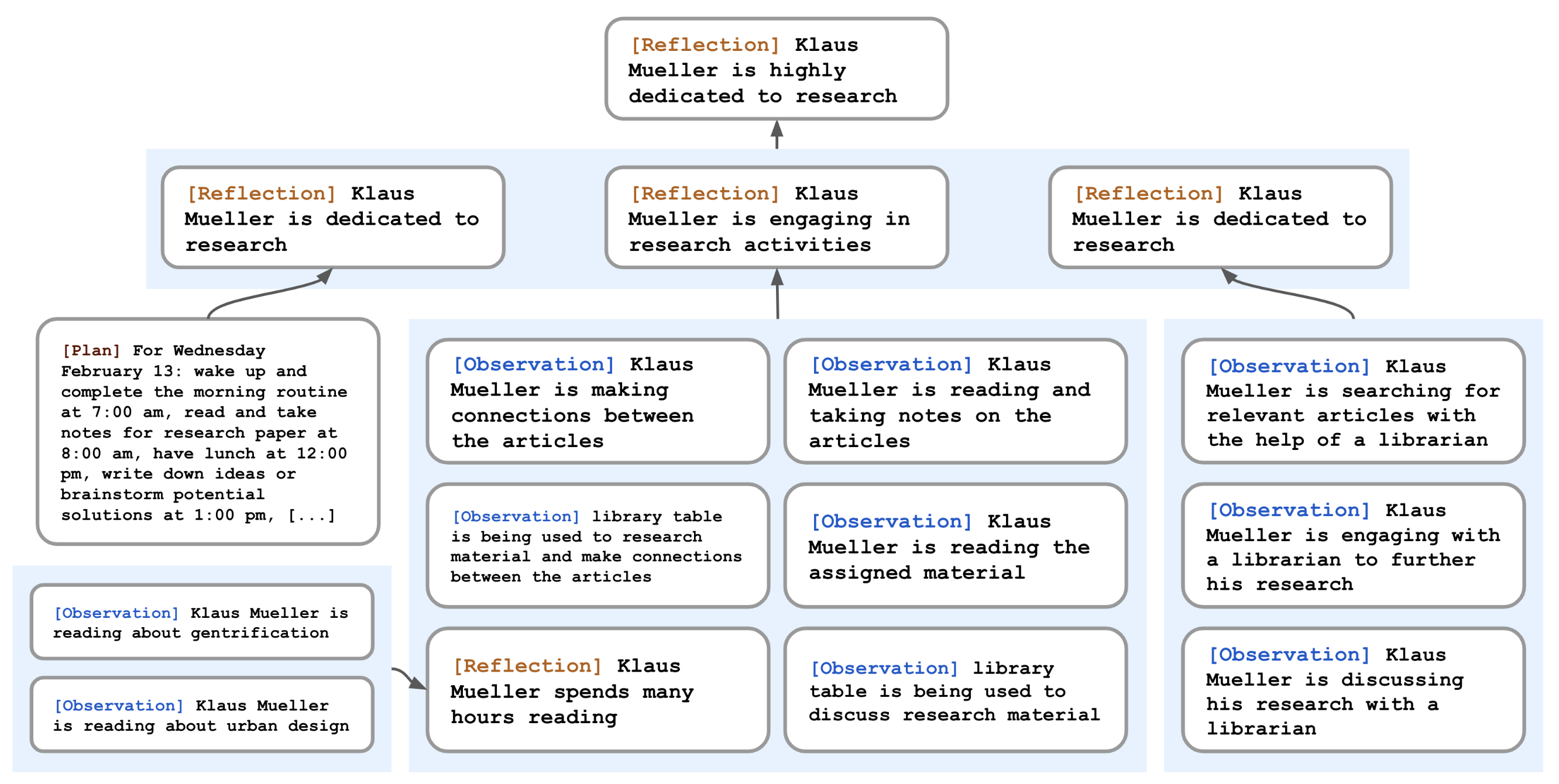
First, the agents needed a way to attend to the proper memory at the right moment. For this, a memory stream retrieval model scored all memories by recency (newer events scored higher), importance (judged by simply asking the LLM), and relevance (to the agents’ current situation), “retrieving” the highest scored memory.
Next, the agents “reflected”. Two to three times daily, agents were asked to generate several high-level questions to ask themselves about their most recent 100 observations. Below is an example of this reflective process:
Next, to maximize human-like behavior, these agents planned their following actions at longish time horizons because, without some foresight, they’d repeat the same steps incoherently (e.g., Klaus would eat lunch at 12, 12:30, and 1 pm). Agents could then react and update plans and actions indefinitely, but Park et al. only simulated for a few days. You can check out a recorded portion of this simulation here.
Similar simulations with cities or nations worth of LLM agents might be helpful tools for studying hypothetical scenarios for behavioral scientists, business leaders, diplomats, or others. They might define agents, an environment, and a time horizon, then let them run and interrogate the results. LLM agent interactions also revolutionize video game dialogue systems by creating more dynamic, convincing non-player characters. But, for now, inference costs make extensive multi-LLM agent interactions prohibitive for many applications.
An LLM Agent Teaches itself to Play Minecraft
LLMs can’t see, so you’d think they’d struggle with complex, open-ended video games like Minecraft. Yet, through language, the LLM agent framework Voyager learned how to interact with animals, deal with hunger, utilize light sources, navigate cave systems, and use increasingly complex tools within Minecraft’s 3-D world. Moreover, Voyager retained what it learned and continuously improved, a feat previously reserved for Reinforcement Learning approaches.
To get it to excel at Minecraft, Wang et al., Voyager’s designers, combined a GPT-4-based agent with tools, memory, and a curriculum. Specifically, Voyager uses GPT-4 to call to the API Mineflayer, which controls Minecraft (i.e., to move around, retrieve items, eliminate foes, etc.). If GPT-4 needs to take an action that it can’t yet do via API calls, it’ll attempt to code a program to accomplish the task.
If that attempt fares well, Voyager archives this “skill” into a “library” (via a vector database) for later use. Eventually, Voyager composes increasingly complex skills from simpler skills, loosely mimicking procedural memory in humans. Voyager learns from two types of error feedback: when one of its self-generated programs (i.e., skills) has a bug and via the game environment itself.
Additionally, Voyager’s “automatic curriculum” serves as its brain. When Voyager receives information about its environment, the GPT-4 reasons about this observation via chain-of-thought prompting, guiding it to explore actions appropriate to its current skill level and environmental state.
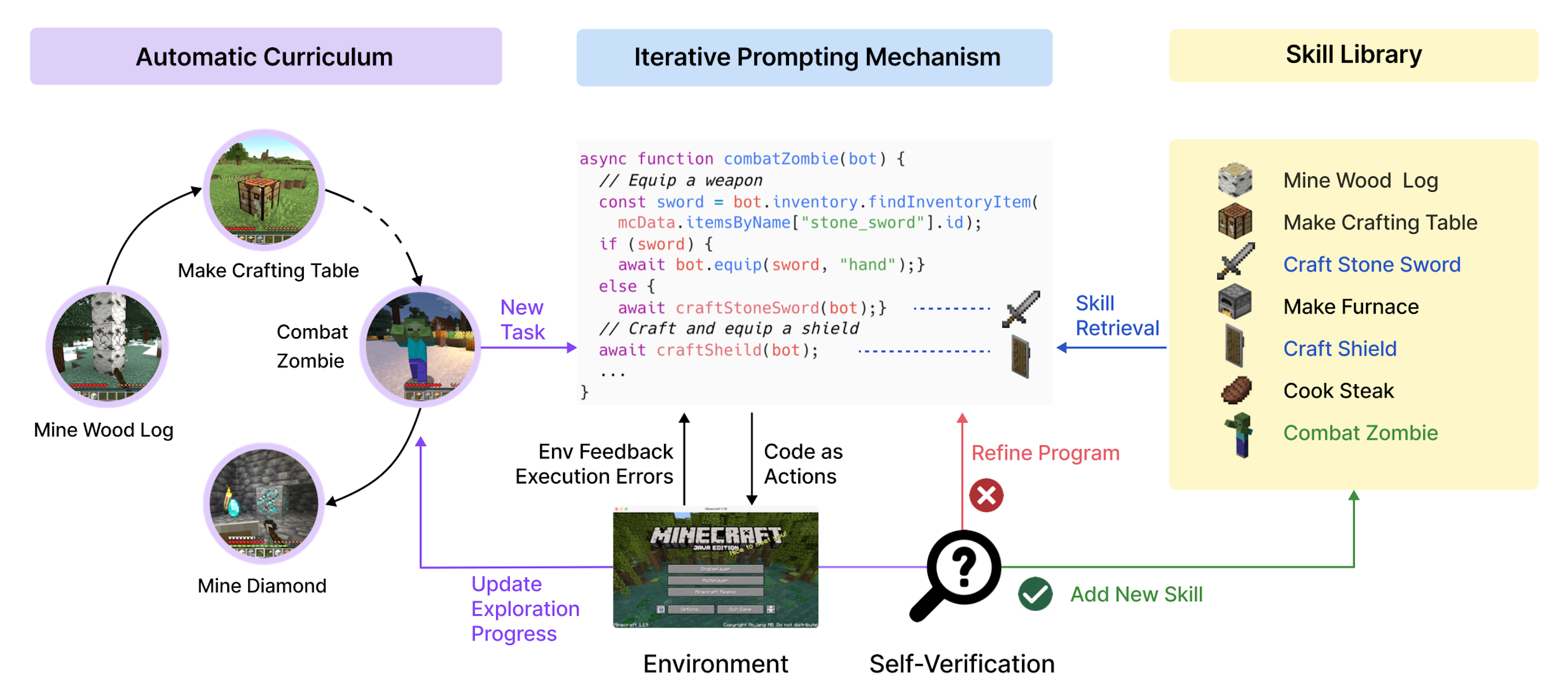
With these pieces in place, Voyager was prompted to "become the best Minecraft player in the world," and, while maybe not the best ever, without direct human intervention (Voyager does benefit from all the human-derived Minecraft wisdom that GPT-4 scooped up during training), it indeed continuously improved its Minecraft chops via exploration and experimentation.
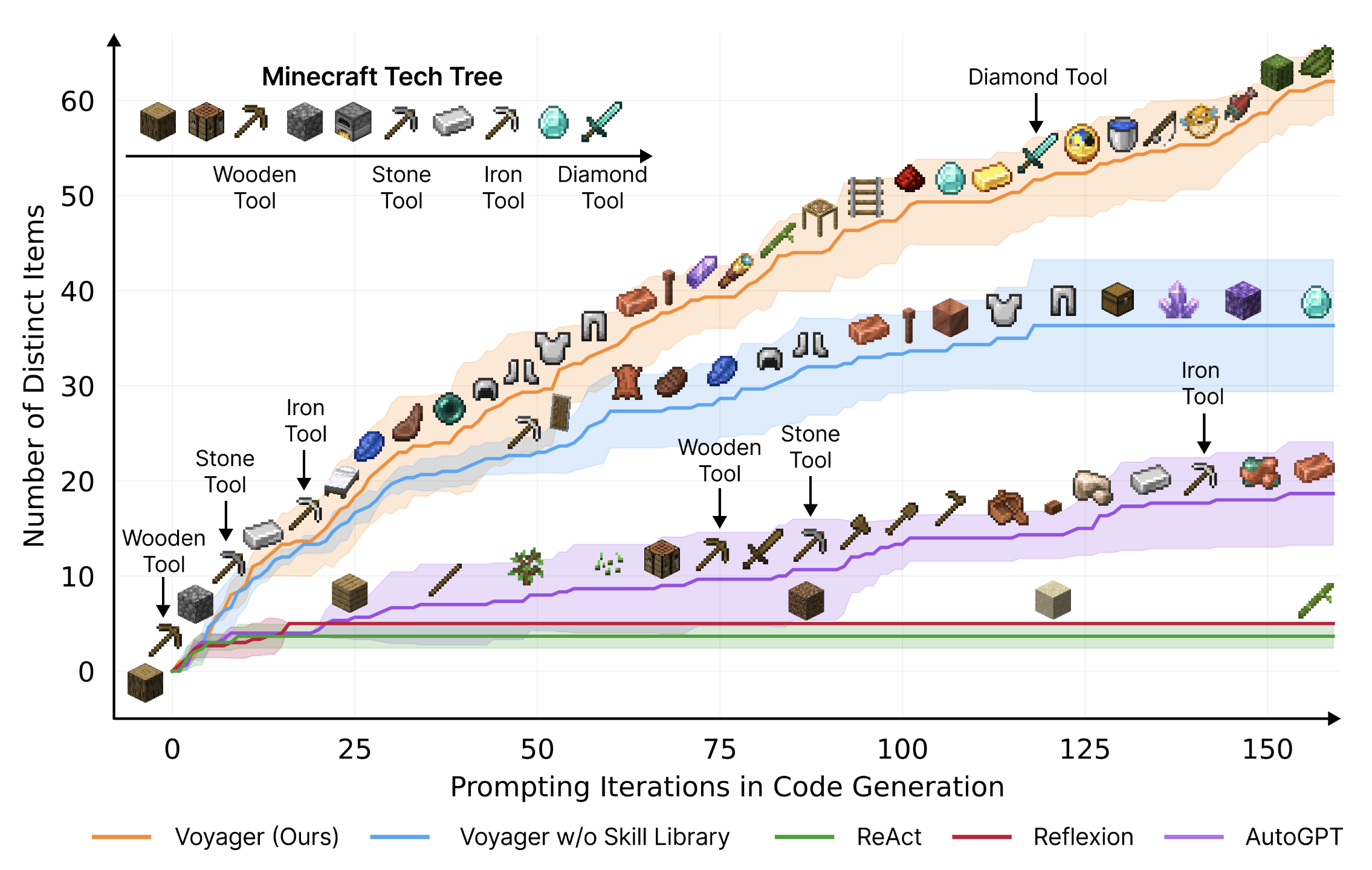
Impressively, Voyager found 3.3 times more unique items, traveled 2.3 times longer distances, and unlocked the tech tree 15.3 times faster than previous automated methods, serving as a proof-of-concept for generalist LLM agents that forego tuning models’ parameters.
LLMs as Tool Makers (LATM)
Inspired by human technological evolution, Cai et al. developed an approach similar to Voyager’s (but outside a video game environment) in their "Large Language Models as Tool Makers" (LATM) paper. With three primary agents—a tool maker, a tool user, and a dispatcher—the LATM framework checks if existing tools are adequate for solving a given task and, if not, generates and employs its own reusable tools (python functions), shedding the dependency on pre-made APIs that many current LLM agent frameworks suffer.
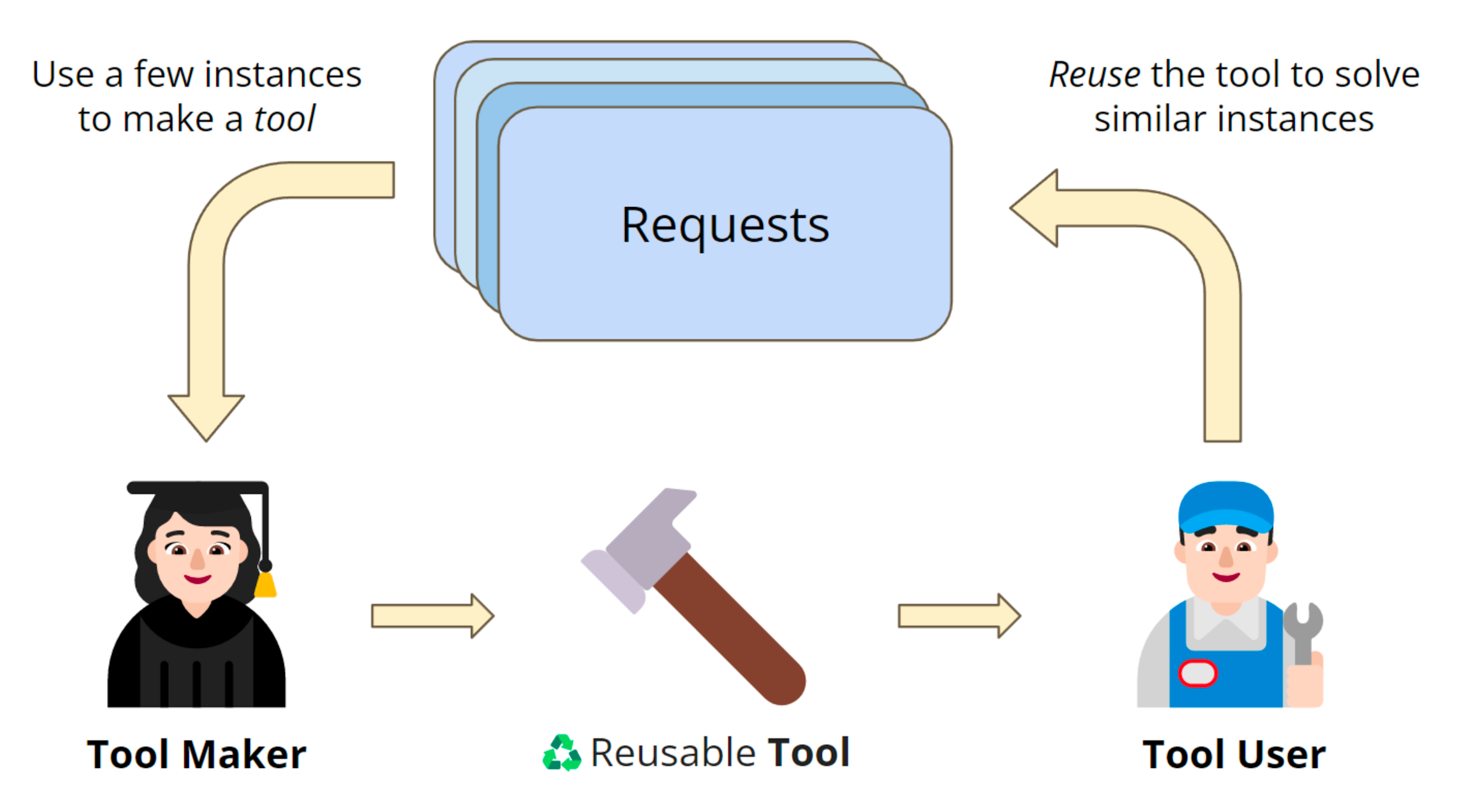
GPT-4 as the tool maker and GPT-3.5 as the tool user achieved nearly the same effectiveness with lower inference costs and speed than GPT-4 for both. This division-of-labor approach could largely improve LLMs’ utility. Imagine if—instead of selecting what three plugins ChatGPT should use for a query—ChatGPT would pick from thousands of relevant plugins and, if none sufficed, code one up itself and then add that to its memory. The LATM approach could significantly broaden LLMs’ capabilities, allowing us to assign LLMs much higher-level goals.
Camel
Using another term for LLM agents, “communicative agents,” Li et al. made Camel. This agent framework employs role-playing and “inception prompting,” with two agents role-playing as different entities autonomously collaborating toward a common objective.
Camel uses the following three agents:
a “user agent” that gives instructions for an objective
an “assistant agent” that generates solutions for the user agent
a “task specifier” agent that causes tasks for the user and assistant agents to complete
A human defines some idea (e.g., making a trading bot) and designates roles for the user and assistant agents (e.g., a Python programmer and a stock trader).
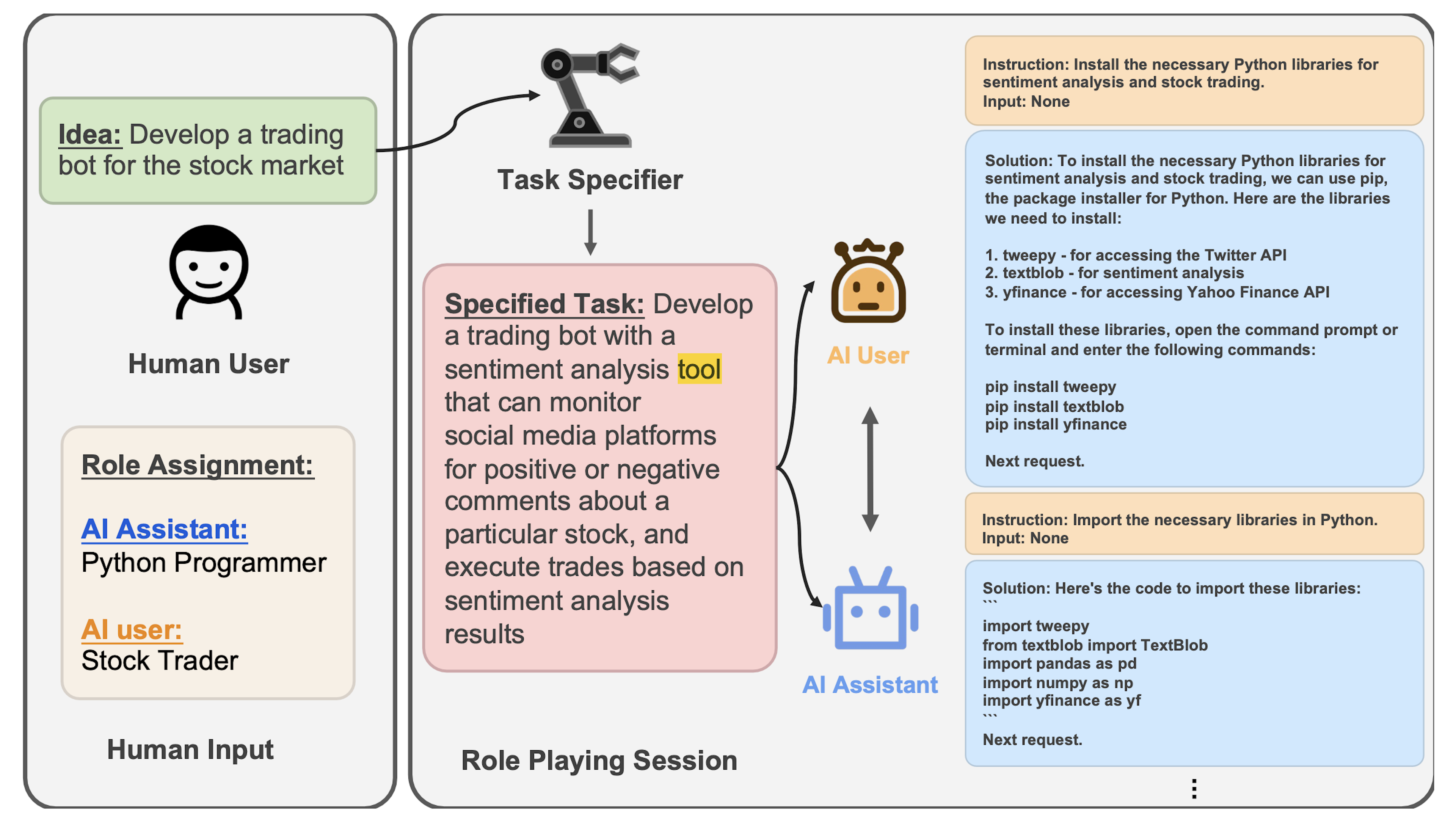
As with most LLM agent frameworks, Camel essentially boils down to careful prompt engineering. However, Camel’s inception prompting uniquely handles all prompting before the two agents interact and never interferes afterward. This means instructing the agents never to flip roles and permanently ending their turn with a ‘next request’ to keep inter-agent dialogue flowing.
You can see what this looks like in the below demo of a computational chemist agent and a poor Ph.D. student interacting to generate a molecular dynamic simulation:
While Camel’s role-playing concept is interesting, their study didn’t hook up their agents to tools or the internet (Camel only spells out the steps one would take), which would make them more useful.
We’ve now completed our tour through recent academic research on LLM agents. Next, let’s check out some independent projects.
Independent Open Source LLM Agent Projects
Haystack, LangChain, Gradio, and many more LLM frameworks now include LLM agent functionality. Taking advantage of these or building from scratch, many folks have cobbled together flawed but interesting LLM agent experiments.
AutoGPT
First up is game developer Toran Bruce Richard’s open-sourced "Auto-GPT," designed to autonomously achieve human-defined goals by using LLM agents to decompose broad goals into sub-tasks and spawn new LLM agents to tackle those.
To use AutoGPT, you define an agent’s
name (e.g., “speech-to-text-GPT”)
role (e.g., “an AI designed to generate new use-cases for existing technology”)
objective (e.g., “brainstorm utterly novel, optionally feasible applications of automated speech-to-text”)
You can also give AutoGPT guiding goals like “research current automated speech-to-text application to rule out what already exists.” AutoGPT then spins up a GPT-3.5-based agent, a GPT-4-based agent, and an orchestrating agent that gives instructions to subordinate GPT-3.5 and GPT-4 agents, generating tasks and executing them.
Using vector database memory to maintain context, AutoGPT ideally loops through this cycle, checking search engines, generating images, employing text-to-speech (if you prefer listening to your agent), or manipulating files as necessary until it accomplishes its assigned objective. AutoGPT has a fully autonomous mode and a mode where, after each cycle of thought --> reasoning --> plan --> criticism, a human must confirm or deny its next proposed action (or provide further guidance).
A few of the many projects inspired by AutoGPT are AgentGPT. In this web browser-based tool, you can try out AutoGPT’s functionality and ChaosGPT, an AutoGPT variant that humorously flailed at its assigned task to “destroy humanity.”
AutoGPT has some significant downsides. First, AutoGPT uses token-intensive chain-of-thought prompting, and it can get stuck in loops, racking up API costs. It also doesn’t yet divide and conquer complex objectives into sub-tasks very well, sometimes exceeding 50 steps just to eke out some nominal sub-task (to say nothing of the broad objective). Additionally, even if you assign Auto-GPT a new task like one already successfully pulled off, it’ll start from scratch; no transfer learning takes place. (Borrowing from Voyager’s approach of storing successful “skills” into a library for later use would help.)
Despite its shortcomings, at a minimum, AutoGPT is an inspiring prototype, with its repo boasting over 31k forks and 145k stars already. With this many people hacking away, it seems inevitable that at least a few of these splintered-off projects will advance AutoGPT’s experimental ideas.
BabyAGI
Born from a desire to mimic his daily routine of creating, prioritizing, and executing tasks, Untapped Capital venture capitalist Yohei Nakajima created BabyAGI, an "AI-powered task management system."
Via GPT-4, open-source vector databases (Chroma or Weaviate), and LangChain, BabyAGI employs the following agents that interact within a “while” loop:
Execution agent
Task creation agent
Prioritization agent
With calls to OpenAI’s API, the task creation agent decomposes a human-defined objective into a task list. Then the prioritization agent, as you’d expect, prioritizes these tasks, stowing them away in a database. Finally, the execution agent takes action on the tasks it can, often revealing and queuing up subsequent jobs. After a reprioritization shuffle, the cycle starts anew. You can see this inter-agent workflow below.
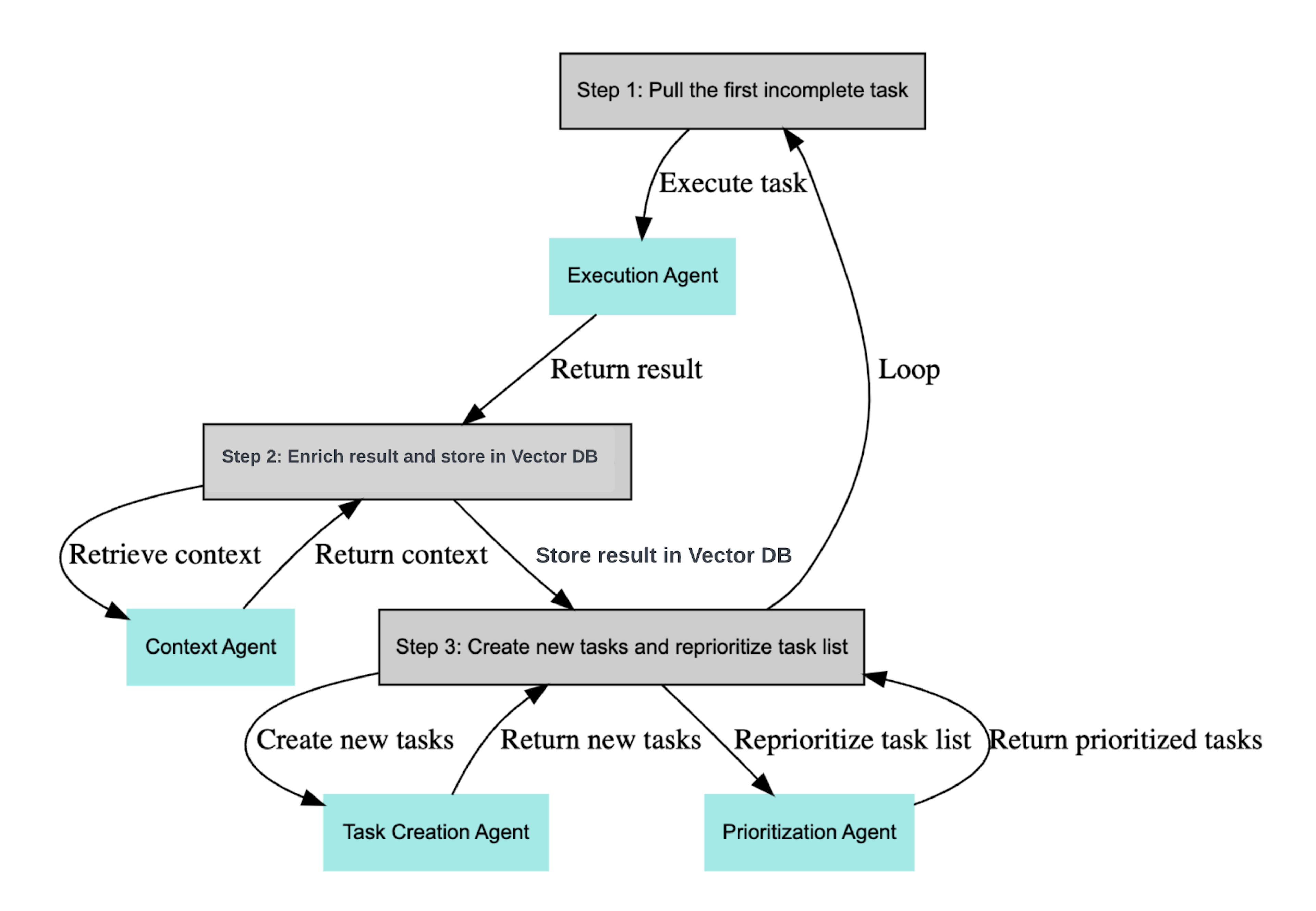
Ideally, this cycle continues until BabyAGI considers the broad objective accomplished, but, like AutoGPT, BabyAGI is also prone to getting stuck along the way.
GPT Researcher
To thoroughly research some topic, there’s no way around chewing your cud, perusing cited sources, checking those sources’ sources, and so on. Sometimes it takes meandering through a labyrinth to find nonobvious, nontrivial connections. For specific goals, though, like staying abreast of some rapidly changing field, the cast-a-wide-net-in-shallow-waters research approach has its merits.
Inspired by AutoGPT and Plan-and-Solve prompting, Wix’s research and development head Assaf Elovic created GPT Researcher to quickly handle this type of quick research, aiming to generate accurate, unbiased, factual research reports automatically.
GPT Researcher shines above manual LLM-based research in two areas. First, it checks sources in parallel (rather than consecutively), speeding up the search process. Second, it accesses updated information. Most current popular chatbots are limited here because they don’t retrieve data in real-time absent some plugin feature. And even when LLMs utilize plugins, they often search the web shallowly, yielding biased, superficial conclusions at the mercy of the SERPs.
GPT Researcher shines above manual LLM-based research in two areas. First, it checks sources in parallel (rather than consecutively), speeding up the search process. Second, it accesses updated information. Most current popular chatbots are limited here because they don’t retrieve data in real-time absent some plugin feature. And even when LLMs utilize plugins, they often search the web shallowly, yielding biased, superficial conclusions at the mercy of the SERPs.
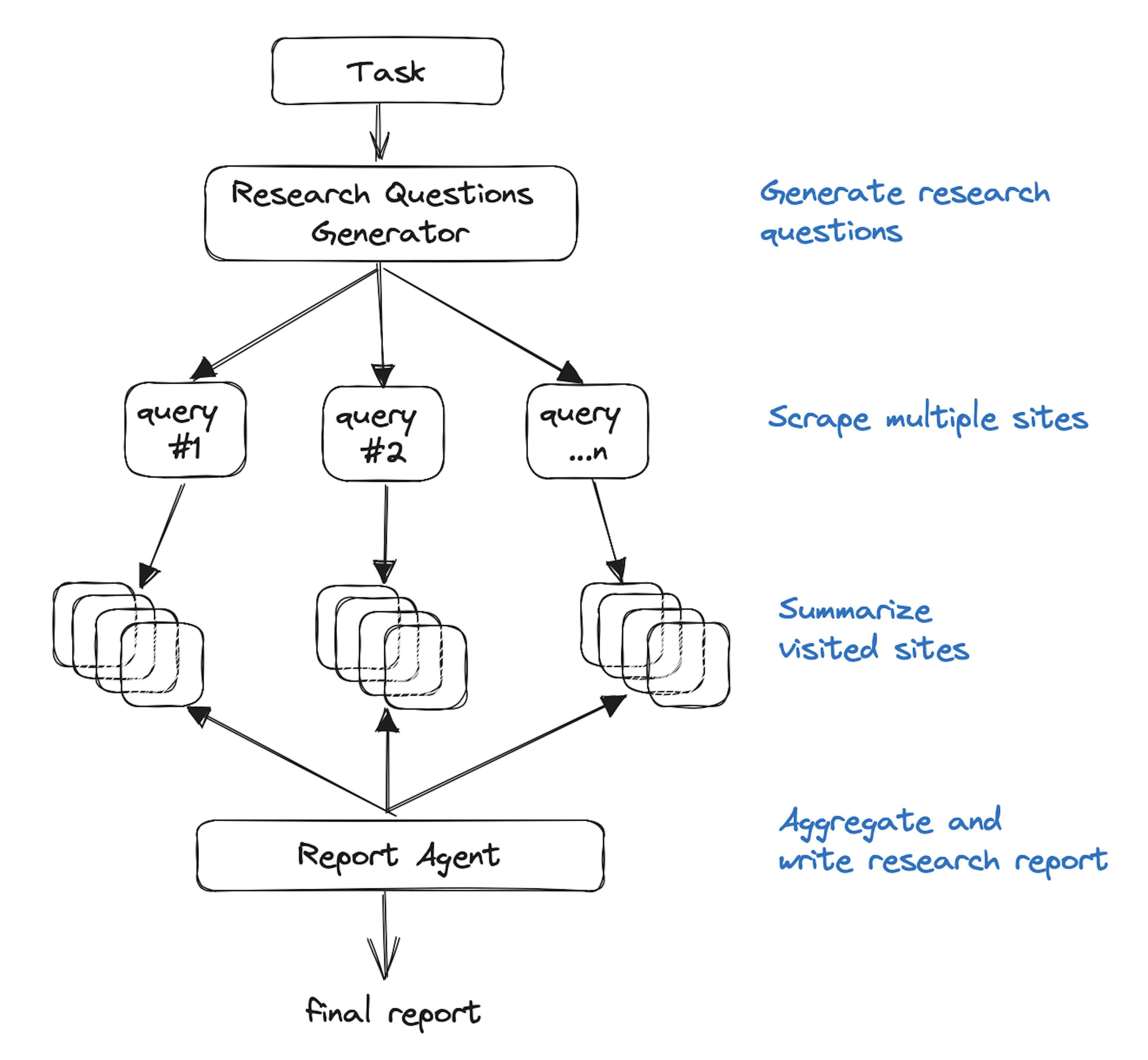
GPT Researcher uses two agents to conduct research relevant to a human-defined task. First, a “planner” creates research questions to guide the study. For each of these questions, an “execution” agent searches for information relevant to the planner’s questions by scraping at least 20 websites from search engine results (hopefully reducing bias and increasing information accuracy), summarizing some number of the most relevant sources, and citing each source that makes the cut. The planner agent then merges the information gleaned by the execution agent into a research report, which you can download as a pdf. You can check out the GPT Researcher demo video or try it out (with an OpenAI API key) here.
LLM Agents
To better grasp their core functionality, Marc Päpper coded a minimalist version of LLM Agents (~100 lines of code), an underappreciated resource.
By including only a few tools, a simple thought —> action —> observation —> thought loop, and elegant stopping logic, his stripped-down repo and accompanying blog post help you see the main moving pieces of LLM agents without getting lost in the weeds. Forking Päpper’s repo is a great way to experiment with an uncomplicated LLM agent.
Morph ChatGPT into a Custom Agent
You don’t necessarily need to dig deep into a full-on agent framework to test these out, though. OpenAI recently released beta "custom interactions" functionality for ChatGPT Plus, allowing you to test agent functionality within ChatGPT.
Via carefully crafted prompts, folks are using this new functionality to generate custom agent behavior akin to what we saw in the above projects. By prepending YouTuber Wes Roth’s suggested edit “This is relevant to EVERY prompt I ask.” to iOS engineer Nick Dobos’ prompt, I asked ChatGPT to generate a few unique speech-to-text use cases and prototypes. Here’s the whole back-and-forth, but one of the more exciting ideas it developed and pseudocode was a speech-to-text graffiti application for VR environments.
Hopefully, you now see why some people are so amped about LLM agents. We’d be remiss, however, not to balance this optimism with sobriety.
Curbed Enthusiasm
For all the LLM agent potential he raved about (in the earlier video), Karpathy also tampered with the hackathon attendees’ enthusiasm, cautioning that LLM agents might take a decade or more to get right (not unlike self-driving vehicles and virtual reality progress).
Echoing Karpathy’s sentiments, software engineer and blogger Matt Rickard also reckons that “autonomous” goal-driven LLM agents are at least a decade out, specifying several key issues we must overcome before we even near “BabyAGI.”
These include reliable translation between natural language and actions (natural language commands don’t deterministically translate to the correct actions). Additionally, inference costs must decrease by a good chunk since agents often must explore many dead ends before finding a solution. LATM’s division of labor approach might address this (assigning more complex tasks to more costly but skilled models, like GPT-4, and more manageable tasks to cheaper, less capable models, like GPT-3.5).
Another deficiency Rickard notes are tool availability; current LLM agents’ actions are often limited to essential tools (e.g., Python RePL, search engines, terminal, APIs, etc.). Rickard likens this to a chicken-and-egg problem; LLM agents’ increased adoption will incentivize companies to create more APIs, and LLM agents’ increased adoption will incentivize companies to develop more APIs. We just need a catalyst to punch through this circular scenario.
The LATM and Voyager approaches can help here, too; if an agent can’t find a suitable API, agents can code up and test their tools, stashing viable tools away for a rainy day. Another helping hand here is Gorilla, a recently released UC Berkeley and Microsoft Research open-source LLM fine-tuned to identify and invoke relevant APIs for tasks implied from natural language.
Thankfully, these open issues don’t seem impossible, and if they’re eventually ironed out, many more people will start doing much more with computers. These days, most people code at higher levels of abstraction than the Assembly language that many programmers previously used daily. LLM agents might—eventually—do the same thing with something like Python, tilting the dominant computer language abstraction level even further from machine code and closer toward human language. Imagine a future where anyone who writes or speaks concisely can spec out entire software projects, and LLMs handle the heavy work. Many folks will have whole new worlds opened to them in computing. LLM agents might make this possible, and that’s ample reason to get excited about them.
Note: If you like this content and would like to learn more, click here! If you want to see a completely comprehensive AI Glossary, click here.




Unlock language AI at scale with an API call.
Get conversational intelligence with transcription and understanding on the world's best speech AI platform.