Whisper-v3 Hallucinations on Real World Data


Last week Sam Altman announced Whisper v3 on stage at OpenAI’s Dev Day. Like any in the community, I was eager to see how the model performed. After all, at Deepgram, we love all things voice AI. Therefore we decided to take it for a spin.
This post shows how I got it running and the results of the testing that I did. Getting the testing setup was relatively straightforward; however, we found some surprising results.
I’ll show some peculiarities up front then go through the thorough analysis after that.
🔍 The Peculiarities We Found
Peculiarity #1:
Start at 4:06 in this audio clip (the same one embedded above). This file is one we used in our testing.
At that moment in the audio, the ground-truth transcription reads “Yeah, I have one Strider XS9. That one’s from 2020. I’ve got two of the Fidgets XSR7s from 2019. And the player tablet is a V2090 that’s dated 2015.”
However, the Whisper-v3 transcript says:

For some reason, the model transcribed the same sentence seven times.
Peculiarity #2:
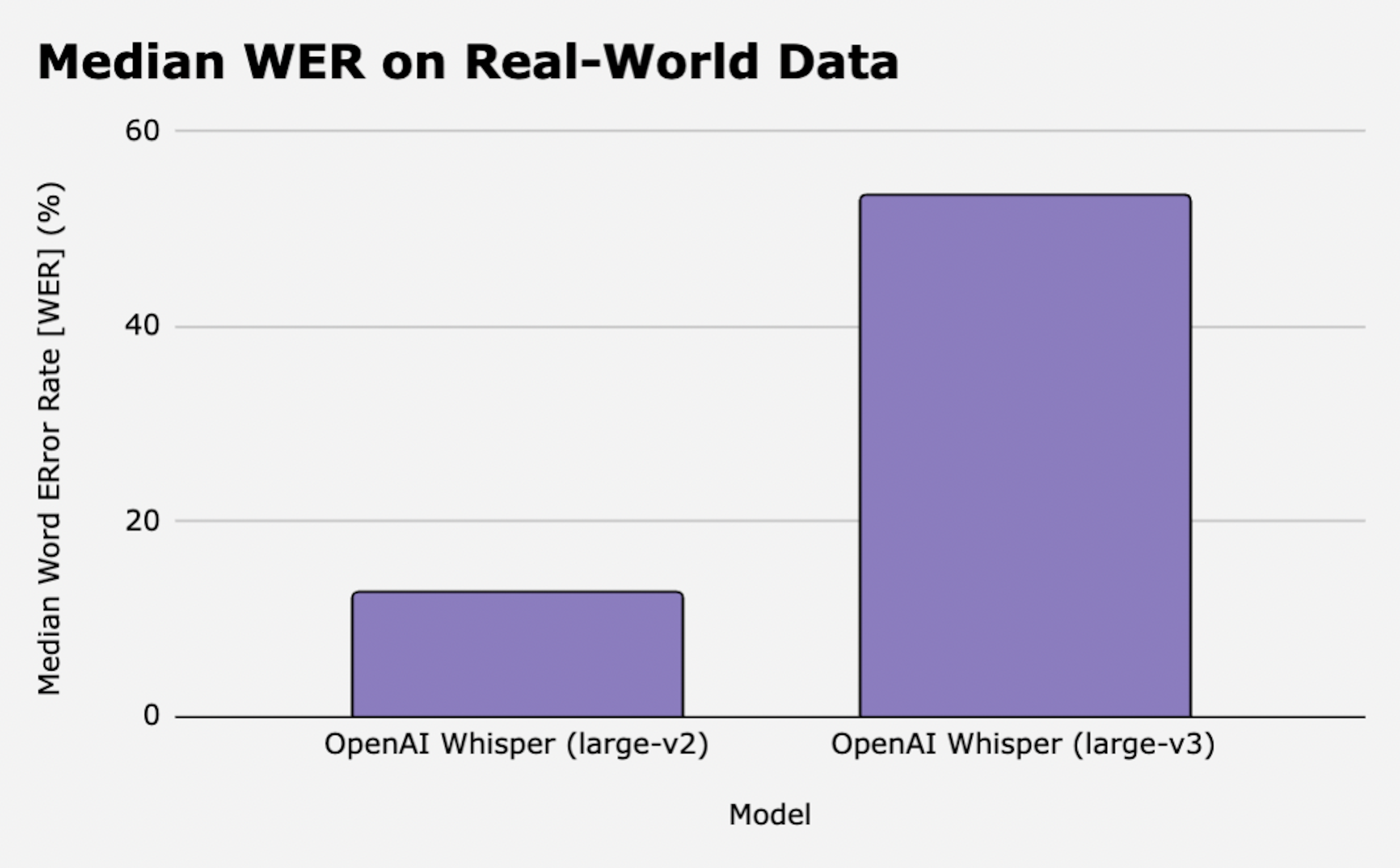
When comparing Whisper-v2 to Whisper-v3 on a larger test suite of real-world data (e.g. videos, phone calls, multi-person conversations, etc.), we found that Whisper-v3 actually hallucinates 4x more often than its predecessor. Or, more specifically, we found a median Word Error Rate (WER) of 53.4 in Whisper-v3 while Whisper-v2 only has a median WER of 12.7.
In other words, Whisper-v3 makes 4x as many mistakes as Whisper-v2.
🧐 I wasn’t the only one who had this result…
The examples above are not cherry-picked. I showcase that display the problem. However, it isn’t all that hard to find such hallucinogenic examples. Overall the stats work out how I noted—4x as many errors as Whisper V2.
And we’re not the only ones noticing hallucinations in Whisper’s outputs. For example, users on the Whisper `large-v3 release` discussion page noted an increase in Word Error Rate.

And when transcribing non-English languages, users report that v3 hallucinates more frequently than v2:

Again the user above is not alone in finding these repetitions and hallucinations occurring in languages like Japanese and Korean.

But even going beyond Github Discussions, we find that users on HackerNews are finding their own hallucinations as well, this time in English.

In fact, there’s a theory that Whisper-v3 simply hallucinates during silence:

But alright, let’s talk about the analysis more thoroughly.
🖼️ Whisper Background
OpenAI’s Whisper has models ranging from 39m params to 1550M params (names tiny, base, small, medium, large). They then released a large-v2 and now a large-v3. This last model is the Whisper-v3 everyone is talking about. My testing today is pitting all the large models against each other. Let me know if you want to see an analysis of all the smaller models too.

Anyway, to the testing setup…
⚒️ Part 1: Setup
First things first, let’s get it set up! The Whisper repo+discussions are located on Github here The repo comes with stats that not only showcase the performance of `large-v3` on the Common Voice 15 dataset, but also the Fleurs dataset. We can also find a Word Error Rate (WER) comparison between v3 and v2 as well:

Benchmarking on academic datasets like Common Voice and FLEURS can give you a quick taste for how a model might perform, but our experience working with demanding enterprise use cases has made us realize that we find better quality signals by running measurements on representative data. Thus, we decided to run our own tests.
Based on the github repo, I created a Colab notebook that you can use to test out some files yourself! Check out that notebook here. It’s built for you to be able to upload and transcribe any audio files you have yourself right now.
Long story short, the first two cells below (1) Install the latest version of the Whisper package and its dependencies, then (2) load the model into a variable named `model` that you can then use to transcribe.
The third cell is where the transcription actually happens.
Depending on your setup (and whether or not you’ve already used Whisper in the past), you may want to check out this repo for additional information.
Now, to upload files into the Google drive, you can simply drag-and-drop any audio or any folders of audios into the side-menu on the left. Then all that's left to do is run the code, and we're all set! Here's what happened next:
🤖 The Output
(Side note: If you want to see Whisper-v3 performance beyond just printing a transcription, click here.)
🚀Part 1: A never-before-seen audio with tough edge-cases
This is the audio I used. It’s brand new because I recorded it on the same day that I wrote the code.
It's particularly tricky because I incorporated a bunch of edge-cases into my utterance. Some of the challenges include:
Jose: A non-English name within an English sentence.
Calinawan: A rare name that both humans and machines have trouble transcribing. Also my real middle name.
O'Hara: I want to test if Whisper will include the apostrophe. Not to mention, the token “O” is tricky, since it can be transcribed as “Oh” or “0” or “O” or “zero,” depending on the context. Not my real last name.
Meta: A more recent entity that may not appear as often as other proper nouns. This one is challenging because the word “meta” can also be used as a common noun as well (ex: a meta joke)
221B Baker Street: An address.
Toucan: A word whose pronunciation can be written as “too, can” or “two can” or “tucan” or “toucan.”
Juan: Another non-English name. Often incorrectly transcribed as “One.”
Oh yeah: Another instance of the word “Oh.”
20/20 vision: I want to test if Whisper will transcribe this as “twenty-twenty” or “2020” or “20 20” or the proper “20/20” or some other approximation.
2019: I want to see how Whisper handles various numbers. Is the presence of a year going to interfere with the phrase “20/20 vision”? Will Whisper instead transcribe this as “twenty-nineteen”?
Uh: I want to see how Whisper handles filler words. Will they be eliminated? Will we get the appropriate punctuation surrounding the filler word? Will it output “uh” or “uhh”?
2023: See ‘2019’ above.

The result?
Not bad! Kalinawan is misspelled, but nobody really gets that on the first try. 20/20 was spelled as 20-20, and Whisper indeed included the filler word “uh” while punctuating it like an appositive. Nevertheless, the punctuation and capitalization are impressive.
As for time, it took 60 seconds to load the model, and two full minutes to transcribe this 13-second audio using the default Google Colab settings (see image below).

📚 Part 2: Overall performance on a larger dataset.
That first test gave me high hopes for this new model. But then something strange happened…
Now, instead of running the code above on a single audio, let’s see what happens when we calculate WER on a larger dataset that contains audios from various domains like phone calls and videos.
For this test, I’ll be using code not from the notebook above, but rather from a more thorough benchmarking and testing suite we built using hours of real-world data such as phone calls, meetings, and YouTube videos.
This is where things got interesting. After my little edge-case sentence above, I had high hopes for this test.
I ended up being more surprised:
WER is off the charts for Whisper-v3, especially when comparing against other ASR providers like AWS, Speechmatics, and Deepgram. While the alternatives make a mistake once every eight to ten words, the benchmark results apparently show that Whisper-v3 makes a mistake once every two words (or worse).

And it gets even more surprising. Check out what happens when we stratify the audio data by domain—from phone calls to videos.

WER is quite literally off the charts. The median word error rate for Whisper-v3 for phone calls is 42.9, which is so high that it’s not even pictured. And I couldn’t even see the reported number for the Meeting domain.
But alright, here’s the raw WER/WRR data for English transcription across various ASR providers:

I figured I must've done something wrong because the results were so off. I checked and double-checked. I restarted everything, I made sure all dependencies were fully updated, I asked a friend to run the code too… And there doesn’t seem to be a problem.
Then I realized that this just must be the true quality of v3.
After looking through the comments on the training of v3, I saw some hints as to what is happening. Then, after reading other folks’ experience via GitHub, I recognized a pattern. These issues are built in. The model has some hallucination problems.
And these hallucinations occur in Whisper-v3 on top of being quite slower than its predecessors. Check me if I am missing something here, but Whisper-v3 doesn’t seem to be an improvement. It actually seems like a regression overall for English. Nonetheless, let me know if you want to see a similar analysis for other languages, I will set some time aside to do it.




Unlock language AI at scale with an API call.
Get conversational intelligence with transcription and understanding on the world's best speech AI platform.